著者 | エコノミスト 翻訳者 |担当編集者 | Xia Meng出品 | CSDN(ID:CSDNnews) 画像ソース: Unbounded AI によって生成AI がより優れたものとなるには、より少ないリソースでより多くのことを行う必要があります。OpenAI の GPT (Generative Pre-trained Transformer) などの「大規模言語モデル」(LLM) について言えば、米国で人気のチャットボットを推進する中核となっており、その名前がすべてを物語っています。このような現代の AI システムは、生物学的な脳の働きを広範囲に模倣する巨大な人工ニューラル ネットワークによって動かされています。 2020 年にリリースされた GPT-3 は、1,750 億個の「パラメーター」を備えた巨大な言語モデルです。パラメーターとは、ニューロン間のシミュレートされた接続の名前です。 GPT-3 は、数千の AI に精通した GPU を使用して数週間で数兆ワードのテキストを処理することによってトレーニングされ、推定コストは 460 万ドル以上です。しかし、現代の AI 研究におけるコンセンサスは、「大きいほど優れており、大きいほど優れている」です。したがって、モデルの規模の成長率は急速に発展しています。 3 月にリリースされた GPT-4 には、約 1 兆個のパラメーターがあると推定されており、これは前世代に比べてほぼ 6 倍に増加しています。 OpenAI CEOのサム・アルトマン氏は、開発に1億ドル以上かかったと見積もっている。そして業界全体としても同様の傾向が見られます。調査会社 Epoch AI は、2022 年にはトップモデルのトレーニングに必要なコンピューティング能力が 6 ~ 10 か月ごとに 2 倍になると予測しています (下のグラフを参照)。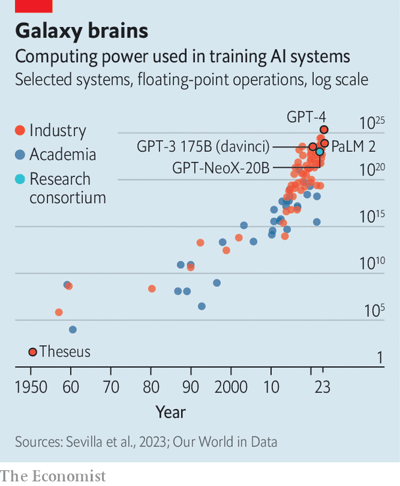 AI モデルのパラメーターのサイズが増大し続けると、いくつかの問題が生じます。 Epoch AI の予測が正しく、トレーニング費用が 10 か月ごとに 2 倍になる場合、トレーニング費用は 2026 年までに 10 億ドルを超える可能性があります。これは、データが最初に枯渇していないことを前提としています。 2022 年 10 月の分析では、トレーニングに使用される高品質のテキストが同じ時間内に使い果たされる可能性があると予測されました。また、モデルのトレーニングが完了した後でも、大規模なモデルを実行する実際のコストは法外に高額になる可能性があります。今年初め、モルガン・スタンレーは、グーグルの検索の半分が現行のGPTタイプのプログラムで処理された場合、同社に年間60億ドルの追加コストがかかる可能性があると試算した。モデルのサイズが大きくなるにつれて、この数値は今後も増加すると考えられます。その結果、AI モデルは「大きいほど良い」という多くの人の見方はもはや通用しません。 AI モデルを改善し続けるつもりなら (AI の壮大な夢を実現するのは言うまでもなく)、開発者は限られたリソースでより良いパフォーマンスを得る方法を見つける必要があります。アルトマン氏は今年4月、大規模AIの歴史を振り返ってこう語った。「私たちは一つの時代の終わりに達したと思う」。## **定量的な処理**代わりに、研究者たちは規模の追求だけでなく、モデルの効率を向上させる方法に焦点を当て始めました。 1 つの方法は、パラメーターの数を減らし、より多くのデータを使用してモデルをトレーニングすることでトレードオフを達成することです。 2022 年、Google の DeepMind 部門は、1 兆 4000 億語のコーパスで Chinchilla と呼ばれる 700 億パラメータの LLM をトレーニングしました。 GPT-3 の 1,750 億より少ないパラメーターとわずか 3,000 億語のトレーニング データにもかかわらず、このモデルは GPT-3 を上回りました。より小さな LLM により多くのデータを供給すると、トレーニングに時間がかかりますが、その結果、より小さく、より高速で、より安価なモデルが得られます。もう 1 つのオプションは、浮動小数点数の精度を下げることです。モデル内の各数値の精度の桁数を減らす (つまり丸め) と、ハードウェア要件を大幅に減らすことができます。オーストリア科学技術研究所の研究者らは3月、丸めによってGPT-3のようなモデルのメモリ消費量を大幅に削減でき、モデルを5台ではなく1台のハイエンドGPUで実行できるようになり、「精度の低下は無視できる」ことを実証した。 「」。一部のユーザーは、法的文書の生成やフェイクニュースの検出などの特定のタスクに焦点を当てるために、汎用 LLM を微調整します。これは LLM を初めてトレーニングするほど複雑ではありませんが、それでも費用と時間がかかる可能性があります。 Meta (Facebook の親会社) がオープンソース化した 650 億パラメータの LLaMA モデルの微調整には複数の GPU が必要で、数時間から数日かかりました。ワシントン大学の研究者らは、パフォーマンス損失を無視して 1 日で 1 つの GPU 上で LLaMA から新しいモデル Guanaco を作成する、より効率的な方法を発明しました。トリックの一部は、オーストリアの研究者が使用したものと同様の丸め手法です。しかし、彼らは低ランク適応 (LoRA) と呼ばれる手法も使用しました。これには、モデルの既存のパラメーターを修正し、新しい小さいパラメーターのセットをそれに追加することが含まれます。微調整は、これらの新しい変数のみを変更することによって行われます。これにより、スマートフォンなどの比較的性能の低いコンピューターでも作業ができるほど作業が簡素化されます。 LLM を現在の巨大なデータセンターではなくユーザーのデバイス上で実行できれば、より高度なパーソナライゼーションとより優れたプライバシー保護がもたらされる可能性があります。一方、Google のチームは、小型モデルでも問題なく使用できるユーザー向けに新しいオプションを提供しています。このアプローチは、大規模な一般モデルから特定の知識をマイニングし、それをより小規模で特殊なモデルに変換することに焦点を当てています。大きなモデルは教師として機能し、小さなモデルは生徒として機能します。研究者らは教師に質問に答えて推論を実証してもらいました。教師モデル (大きなモデル) からの回答と推論の両方が、学生モデル (小さなモデル) のトレーニングに使用されます。チームは、わずか 77 億のパラメータを持つ学生モデル (小規模モデル) をトレーニングし、特定の推論タスクで 5,400 億のパラメータを持つ教師モデル (大規模モデル) を上回るパフォーマンスを発揮することに成功しました。もう 1 つのアプローチは、モデルの動作に焦点を当てるのではなく、モデルの構築方法を変更することです。ほとんどの AI モデルは Python 言語で開発されています。使いやすいように設計されており、プログラマーは、プログラムが実行中にチップをどのように操作するかを考える必要がなくなります。これらの詳細をマスクすると、コードの実行が遅くなります。これらの実装の詳細にさらに注意を払うと、大きな成果が得られる可能性があります。オープンソース AI 企業ハギング フェイスの最高科学責任者であるトーマス ウルフ氏は、これは「人工知能における現在の研究の重要な側面」であると述べています。## **最適化されたコード**たとえば、2022 年にスタンフォード大学の研究者は、大規模言語モデル (LLM) が単語と概念の間のつながりを学習できるようにする「注意アルゴリズム」の改良版をリリースしました。アイデアは、コードが実行されているチップ上で何が起こっているかを考慮してコードを変更し、特に特定の情報をいつ取得または保存する必要があるかを追跡することです。彼らのアルゴリズムは、初期の大規模言語モデルである GPT-2 のトレーニング速度を 3 倍にすることに成功し、さらに長いクエリを処理する能力も強化しました。**より優れたツールを使用すると、よりクリーンなコードを実現することもできます**。今年の初めに、Meta は AI プログラミング フレームワークの新バージョンである PyTorch をリリースしました。プログラマーに実際のチップ上で計算を編成する方法をさらに考えてもらうことで、コードを 1 行追加するだけでモデルをトレーニングできる速度を 2 倍にすることができます。元AppleとGoogleのエンジニアによって設立された新興企業Modularは先月、PythonをベースにしたMojoと呼ばれるAIに特化した新しいプログラミング言語をリリースした。 Mojo を使用すると、これまでシールドされていたすべての詳細をプログラマーが制御できるようになり、場合によっては、Mojo を使用して作成されたコードは、Python で作成された同等のコード ブロックよりも数千倍高速に実行できます。**最後のオプションは、コードを実行するチップを改良することです**。もともと、GPU は現代のビデオ ゲームに見られる複雑なグラフィックスを処理するように設計されていましたが、驚くほど AI モデルの実行に優れています。 Meta のハードウェア研究者は、「推論」(つまり、トレーニング後のモデルの実際の実行)のために、GPU は完全には設計されていないと述べました。その結果、一部の企業は独自のより特殊なハードウェアを設計しています。 GoogleはすでにAIプロジェクトのほとんどを自社製「TPU」チップ上で実行している。 MTIA チップを搭載した Meta と、Inferentia チップを搭載した Amazon も同様のことを試みています。驚くべきことに、数値の四捨五入やプログラミング言語の切り替えなどの単純な変更によって、パフォーマンスが大幅に向上することがあります。しかし、これは大規模言語モデル (LLM) の急速な発展を反映しています。長年にわたり、大規模な言語モデルは主に研究プロジェクトであり、デザインの優雅さよりも、言語モデルを動作させて有効な結果を生み出すことに主に重点が置かれていました。それらが商用の大量市場向け製品になったのはつい最近のことです。ほとんどの専門家は、改善の余地がたくさんあることに同意しています。スタンフォード大学のコンピューター科学者であるクリス・マニング氏は、「現在使用されているニューラル アーキテクチャ(現在のニューラル ネットワーク構造を指す)が最適であると信じる理由はなく、より高度なアーキテクチャが登場する可能性も排除されない」と述べています。将来。"
AI モデルの「大きいことは良いこと」の観点はもはや機能しない
著者 | エコノミスト 翻訳者 |
担当編集者 | Xia Meng
出品 | CSDN(ID:CSDNnews)
AI がより優れたものとなるには、より少ないリソースでより多くのことを行う必要があります。
OpenAI の GPT (Generative Pre-trained Transformer) などの「大規模言語モデル」(LLM) について言えば、米国で人気のチャットボットを推進する中核となっており、その名前がすべてを物語っています。このような現代の AI システムは、生物学的な脳の働きを広範囲に模倣する巨大な人工ニューラル ネットワークによって動かされています。 2020 年にリリースされた GPT-3 は、1,750 億個の「パラメーター」を備えた巨大な言語モデルです。パラメーターとは、ニューロン間のシミュレートされた接続の名前です。 GPT-3 は、数千の AI に精通した GPU を使用して数週間で数兆ワードのテキストを処理することによってトレーニングされ、推定コストは 460 万ドル以上です。
しかし、現代の AI 研究におけるコンセンサスは、「大きいほど優れており、大きいほど優れている」です。したがって、モデルの規模の成長率は急速に発展しています。 3 月にリリースされた GPT-4 には、約 1 兆個のパラメーターがあると推定されており、これは前世代に比べてほぼ 6 倍に増加しています。 OpenAI CEOのサム・アルトマン氏は、開発に1億ドル以上かかったと見積もっている。そして業界全体としても同様の傾向が見られます。調査会社 Epoch AI は、2022 年にはトップモデルのトレーニングに必要なコンピューティング能力が 6 ~ 10 か月ごとに 2 倍になると予測しています (下のグラフを参照)。
今年初め、モルガン・スタンレーは、グーグルの検索の半分が現行のGPTタイプのプログラムで処理された場合、同社に年間60億ドルの追加コストがかかる可能性があると試算した。モデルのサイズが大きくなるにつれて、この数値は今後も増加すると考えられます。
その結果、AI モデルは「大きいほど良い」という多くの人の見方はもはや通用しません。 AI モデルを改善し続けるつもりなら (AI の壮大な夢を実現するのは言うまでもなく)、開発者は限られたリソースでより良いパフォーマンスを得る方法を見つける必要があります。アルトマン氏は今年4月、大規模AIの歴史を振り返ってこう語った。「私たちは一つの時代の終わりに達したと思う」。
定量的な処理
代わりに、研究者たちは規模の追求だけでなく、モデルの効率を向上させる方法に焦点を当て始めました。 1 つの方法は、パラメーターの数を減らし、より多くのデータを使用してモデルをトレーニングすることでトレードオフを達成することです。 2022 年、Google の DeepMind 部門は、1 兆 4000 億語のコーパスで Chinchilla と呼ばれる 700 億パラメータの LLM をトレーニングしました。 GPT-3 の 1,750 億より少ないパラメーターとわずか 3,000 億語のトレーニング データにもかかわらず、このモデルは GPT-3 を上回りました。より小さな LLM により多くのデータを供給すると、トレーニングに時間がかかりますが、その結果、より小さく、より高速で、より安価なモデルが得られます。
もう 1 つのオプションは、浮動小数点数の精度を下げることです。モデル内の各数値の精度の桁数を減らす (つまり丸め) と、ハードウェア要件を大幅に減らすことができます。オーストリア科学技術研究所の研究者らは3月、丸めによってGPT-3のようなモデルのメモリ消費量を大幅に削減でき、モデルを5台ではなく1台のハイエンドGPUで実行できるようになり、「精度の低下は無視できる」ことを実証した。 「」。
一部のユーザーは、法的文書の生成やフェイクニュースの検出などの特定のタスクに焦点を当てるために、汎用 LLM を微調整します。これは LLM を初めてトレーニングするほど複雑ではありませんが、それでも費用と時間がかかる可能性があります。 Meta (Facebook の親会社) がオープンソース化した 650 億パラメータの LLaMA モデルの微調整には複数の GPU が必要で、数時間から数日かかりました。
ワシントン大学の研究者らは、パフォーマンス損失を無視して 1 日で 1 つの GPU 上で LLaMA から新しいモデル Guanaco を作成する、より効率的な方法を発明しました。トリックの一部は、オーストリアの研究者が使用したものと同様の丸め手法です。しかし、彼らは低ランク適応 (LoRA) と呼ばれる手法も使用しました。これには、モデルの既存のパラメーターを修正し、新しい小さいパラメーターのセットをそれに追加することが含まれます。微調整は、これらの新しい変数のみを変更することによって行われます。これにより、スマートフォンなどの比較的性能の低いコンピューターでも作業ができるほど作業が簡素化されます。 LLM を現在の巨大なデータセンターではなくユーザーのデバイス上で実行できれば、より高度なパーソナライゼーションとより優れたプライバシー保護がもたらされる可能性があります。
一方、Google のチームは、小型モデルでも問題なく使用できるユーザー向けに新しいオプションを提供しています。このアプローチは、大規模な一般モデルから特定の知識をマイニングし、それをより小規模で特殊なモデルに変換することに焦点を当てています。大きなモデルは教師として機能し、小さなモデルは生徒として機能します。研究者らは教師に質問に答えて推論を実証してもらいました。教師モデル (大きなモデル) からの回答と推論の両方が、学生モデル (小さなモデル) のトレーニングに使用されます。チームは、わずか 77 億のパラメータを持つ学生モデル (小規模モデル) をトレーニングし、特定の推論タスクで 5,400 億のパラメータを持つ教師モデル (大規模モデル) を上回るパフォーマンスを発揮することに成功しました。
もう 1 つのアプローチは、モデルの動作に焦点を当てるのではなく、モデルの構築方法を変更することです。ほとんどの AI モデルは Python 言語で開発されています。使いやすいように設計されており、プログラマーは、プログラムが実行中にチップをどのように操作するかを考える必要がなくなります。これらの詳細をマスクすると、コードの実行が遅くなります。これらの実装の詳細にさらに注意を払うと、大きな成果が得られる可能性があります。オープンソース AI 企業ハギング フェイスの最高科学責任者であるトーマス ウルフ氏は、これは「人工知能における現在の研究の重要な側面」であると述べています。
最適化されたコード
たとえば、2022 年にスタンフォード大学の研究者は、大規模言語モデル (LLM) が単語と概念の間のつながりを学習できるようにする「注意アルゴリズム」の改良版をリリースしました。アイデアは、コードが実行されているチップ上で何が起こっているかを考慮してコードを変更し、特に特定の情報をいつ取得または保存する必要があるかを追跡することです。彼らのアルゴリズムは、初期の大規模言語モデルである GPT-2 のトレーニング速度を 3 倍にすることに成功し、さらに長いクエリを処理する能力も強化しました。
より優れたツールを使用すると、よりクリーンなコードを実現することもできます。今年の初めに、Meta は AI プログラミング フレームワークの新バージョンである PyTorch をリリースしました。プログラマーに実際のチップ上で計算を編成する方法をさらに考えてもらうことで、コードを 1 行追加するだけでモデルをトレーニングできる速度を 2 倍にすることができます。元AppleとGoogleのエンジニアによって設立された新興企業Modularは先月、PythonをベースにしたMojoと呼ばれるAIに特化した新しいプログラミング言語をリリースした。 Mojo を使用すると、これまでシールドされていたすべての詳細をプログラマーが制御できるようになり、場合によっては、Mojo を使用して作成されたコードは、Python で作成された同等のコード ブロックよりも数千倍高速に実行できます。
最後のオプションは、コードを実行するチップを改良することです。もともと、GPU は現代のビデオ ゲームに見られる複雑なグラフィックスを処理するように設計されていましたが、驚くほど AI モデルの実行に優れています。 Meta のハードウェア研究者は、「推論」(つまり、トレーニング後のモデルの実際の実行)のために、GPU は完全には設計されていないと述べました。その結果、一部の企業は独自のより特殊なハードウェアを設計しています。 GoogleはすでにAIプロジェクトのほとんどを自社製「TPU」チップ上で実行している。 MTIA チップを搭載した Meta と、Inferentia チップを搭載した Amazon も同様のことを試みています。
驚くべきことに、数値の四捨五入やプログラミング言語の切り替えなどの単純な変更によって、パフォーマンスが大幅に向上することがあります。しかし、これは大規模言語モデル (LLM) の急速な発展を反映しています。長年にわたり、大規模な言語モデルは主に研究プロジェクトであり、デザインの優雅さよりも、言語モデルを動作させて有効な結果を生み出すことに主に重点が置かれていました。それらが商用の大量市場向け製品になったのはつい最近のことです。ほとんどの専門家は、改善の余地がたくさんあることに同意しています。スタンフォード大学のコンピューター科学者であるクリス・マニング氏は、「現在使用されているニューラル アーキテクチャ(現在のニューラル ネットワーク構造を指す)が最適であると信じる理由はなく、より高度なアーキテクチャが登場する可能性も排除されない」と述べています。将来。"