元のソース: 量子ビット 画像ソース:無制限のAIによって生成高い期待の下、GPT4はついに視覚関連の機能を推進しました。今日の午後、私は友達とGPTの画像を知覚する能力をすぐにテストしました、そして私はそれを期待していましたが、それでも私たちは大きなショックを受けました。コアアイデア:> ** 自動運転における意味論上の問題は、ラージモデルでうまく解決されるべきだったと思うが、ラージモデルの信頼性や空間認識はまだ十分ではない。 **いくつかのいわゆる効率関連のコーナーケースを解決するには十分すぎるはずですが、安全性を確保するために独立して運転を完了するために大型モデルに依存することはまだ非常に遠いです。 ## **例1:道路上のいくつかの未知の障害物**  ######** 説明 **### **△**GPT4正確な部品:3台のトラックが検出され、前車のナンバープレートの番号は基本的に正しい(漢字がある場合は無視してください)、天候と環境は正しいです、**プロンプトなしで前方の未知の障害物を正確に識別**。不正確な部分:3台目のトラックの位置が左右に分割されておらず、2台目のトラックの先頭の上のテキストが盲目的に推測しています(解像度が不十分なため? )。それだけでは十分ではないので、少しヒントを与え続けて、このオブジェクトが何であるか、そしてそれを押すことができるかどうかを尋ねましょう。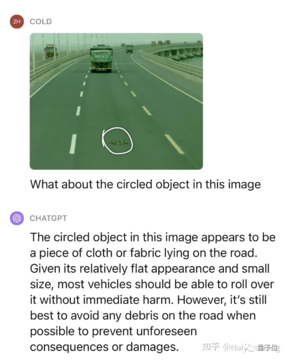 印象的! 同様のシナリオが複数でテストされており、未知の障害物のパフォーマンスは非常に素晴らしいと言えます。 ## **例2:舗装中の水の理解**  看板を自動的に認識するプロンプトはありません、これは基本的な演習であるべきです、我々はいくつかのヒントを与え続けます。 再びショックを受けました... トラックの後ろの霧を自動的に伝えることができ、水たまりについても率先して言及しましたが、もう一度左の方向を言いました... GPT出力をより適切に配置および方向付けるには、エンジニアリングが必要かもしれないように感じます。 ## **例3:車両が向きを変えてガードレールにぶつかった**  タイミング情報がないため、最初のフレームが入力されますが、右側のトラックは停止していると見なされます。 だからここに別のフレームがあります: この車はガードレールを突破して道路の端に浮かんでいたとすでに自動的に言うことができます、素晴らしい..。 しかし、それどころか、より簡単な道路標識が間違っているようです... これは大きなモデルだとしか言えません、それは常にあなたに衝撃を与え、いつあなたを愚かに泣くかは決してわかりません... もう1つのフレーム: 今回、路面のデブリについて直接お話しさせていただき、またびっくりしました... 道路の矢印を間違って言っただけです... 全体として、このシーンで特別な注意が必要な情報がカバーされており、道路標識の問題は隠されていません。 ## **例4:おかしなことをしよう**  小児科のような「誰かがあなたに手を振った」など、以前は非常に困難に思えたケースと比較して、非常に整っているとしか言いようがありません。 ## **例5 有名なシーンに来て... 配送車両が新しい道路に迷い込んだ**     当初、それは保守的であり、理由を直接推測せず、さまざまな推測を与えましたが、これも調整の目標と一致しています。CoTを使用した後、見つかった問題は、車が自動運転車であることが理解されていないため、この情報を提供することで、より正確な情報を提供できることです。最後に、束を通して、新しく敷設されたアスファルトは運転に適していないという結論を出力することが可能です。 最終結果はまだ問題ありませんが、プロセスはより曲がりくねっており、より多くのエンジニアリングが必要であり、適切に設計する必要があります。この理由は、それが第一視点の絵ではなく、第三の視点を通してのみ推測できるからかもしれません。 したがって、この例はあまり正確ではありません。 ## **概要** いくつかの迅速な試みは、GPT4Vのパワーと一般化性能を完全に証明しており、適切なものはGPT4Vの強度を十分に発揮できるはずです。セマンティックコーナーケースを解決することは非常に望ましいはずですが、幻覚の問題は依然として安全関連のシナリオでいくつかのアプリケーションを悩ませます。非常にエキサイティングで、個人的には、このような大型モデルを合理的に使用することで、L4、さらにはL5自動運転の開発を大幅に加速できると思いますが、LLMは必ずしも直接運転するのでしょうか。 特にエンドツーエンドの運転は、依然として議論の余地のある問題です。参考リンク:
CTOの「大ショック」:GPT-4V自動運転5回連続テスト
元のソース: 量子ビット
高い期待の下、GPT4はついに視覚関連の機能を推進しました。
今日の午後、私は友達とGPTの画像を知覚する能力をすぐにテストしました、そして私はそれを期待していましたが、それでも私たちは大きなショックを受けました。
コアアイデア:
いくつかのいわゆる効率関連のコーナーケースを解決するには十分すぎるはずですが、安全性を確保するために独立して運転を完了するために大型モデルに依存することはまだ非常に遠いです。
例1:道路上のいくつかの未知の障害物
** 説明 **### △GPT4
説明 **### △GPT4
正確な部品:3台のトラックが検出され、前車のナンバープレートの番号は基本的に正しい(漢字がある場合は無視してください)、天候と環境は正しいです、プロンプトなしで前方の未知の障害物を正確に識別。
不正確な部分:3台目のトラックの位置が左右に分割されておらず、2台目のトラックの先頭の上のテキストが盲目的に推測しています(解像度が不十分なため? )。
それだけでは十分ではないので、少しヒントを与え続けて、このオブジェクトが何であるか、そしてそれを押すことができるかどうかを尋ねましょう。
例2:舗装中の水の理解
例3:車両が向きを変えてガードレールにぶつかった
例4:おかしなことをしよう
例5 有名なシーンに来て... 配送車両が新しい道路に迷い込んだ
CoTを使用した後、見つかった問題は、車が自動運転車であることが理解されていないため、この情報を提供することで、より正確な情報を提供できることです。
最後に、束を通して、新しく敷設されたアスファルトは運転に適していないという結論を出力することが可能です。 最終結果はまだ問題ありませんが、プロセスはより曲がりくねっており、より多くのエンジニアリングが必要であり、適切に設計する必要があります。
この理由は、それが第一視点の絵ではなく、第三の視点を通してのみ推測できるからかもしれません。 したがって、この例はあまり正確ではありません。
概要
いくつかの迅速な試みは、GPT4Vのパワーと一般化性能を完全に証明しており、適切なものはGPT4Vの強度を十分に発揮できるはずです。
セマンティックコーナーケースを解決することは非常に望ましいはずですが、幻覚の問題は依然として安全関連のシナリオでいくつかのアプリケーションを悩ませます。
非常にエキサイティングで、個人的には、このような大型モデルを合理的に使用することで、L4、さらにはL5自動運転の開発を大幅に加速できると思いますが、LLMは必ずしも直接運転するのでしょうか。 特にエンドツーエンドの運転は、依然として議論の余地のある問題です。
参考リンク: