出典:新志源 画像ソース: Unbounded AIによって生成自社開発の第3世代台座モデル「ChatGLM3」を本日発売!これは、6月に第2世代モデルが発売されて以来、Zhipu AIチームによるChatGLMベースモデルの最適化です。さらに、10月27日に開催された2023 China Computer Conference(CNCC)で、Zhipu AIはChatGLM3-6B(32k)、マルチモーダルCogVLM-17B、エージェントAgentLMもオープンソース化しました。ChatGLM3シリーズのモデルリリース後、ZhipuはOpenAIのフルモデル製品ラインをベンチマークした中国で唯一の企業となった。 ジェネレーティブAIアシスタントのZhipu Qingyanも、中国で初めてコードインタラクション機能を搭載した大規模モデル製品となった。このモデルは完全に自社開発されており、国産チップに適応し、より強力なパフォーマンスとよりオープンソースのエコシステムを備えています。大規模模型研究に参入した最初の企業として、Zhipu AIが最初に論文を提出しました!さらに、Zhipu AIは今年、美団、蟻、アリババ、テンセントなど、合計25億元以上の資金調達を完了しました。 豪華な投資家のリストはすべて、Zhipu AIに対する業界の強い信頼を示しています。 ## **GPT-4Vの技術向上を目指して** 現在、マルチモーダルビジョンモデルGPT-4Vは、強力な画像認識能力を示しています。同時に、GPT-4Vを目指して、Zhipu AIは今回、ChatGLM3の他の機能も繰り返しアップグレードしました。 その中で、マルチモーダル理解モデルCogVLMは、10+の国際標準グラフィックおよびテキスト評価データセットSOTAを理解し、更新しようとすることができます。 現在、CogVLM-17Bはオープンソース化されています。Code Interpreterは、ユーザーのニーズに応じてコードを生成および実行し、データ分析やファイル処理などの複雑なタスクを自動的に完了できます。Web検索はWebGLMを強化し、質問に応じてインターネット上の関連情報を自動的に検索し、回答時に参照文献や記事へのリンクを提供します。さらに、ChatGLM3 のセマンティックおよび論理機能も大幅に強化されています。### **バージョン6Bダイレクトオープンソース**特筆すべきは、ChatGLM3がリリースされると、Zhipu AIが6Bパラメータモデルをコミュニティに直接オープンソース化したことです。評価結果によると、ChatGLM2と比較し、同じサイズの国内モデルと比較して、ChatGLM3-6Bは44の中国語と英語の公開データセットテストのうち9つで1位でした。MMLUは36%、Cは33%、GSM8Kは179%、BBHは126%増加しました。オープンソースの32kバージョンであるChatGLM3-6B-32Kは、LongBenchで最高のパフォーマンスを発揮します。また、現在の推論フレームワークを同じハードウェア・モデル条件でより効率的にする最新の「効率的動的推論+映像メモリ最適化技術」です。バークレー大学が立ち上げたvLLMや最新バージョンのHugging Face TGIと比較すると、推論速度は2〜3倍、推論コストは1倍に削減され、1000トークンあたり0.5ポイントしかなく、最も低いコストです。### **自社開発のAgentTuning、エージェントの能力発動**さらに驚くべきことに、ChatGLM3 には新しいエージェント機能も搭載されています。Zhipu AIは、大規模なモデルがAPIを介して外部ツールとより適切に通信し、エージェントを介して大規模なモデルの相互作用を実現できることを期待しています。自社開発のAgentTuningテクノロジーを統合することで、特にインテリジェントな計画と実行の面で、モデルのインテリジェントエージェント機能を活性化することができ、ChatGLM 2よりも1000%高くなっています。最新のAgentBenchでは、ChatGLM3-turboはGPT-3.5に近いです。同時に、AgentLMはオープンソースコミュニティにも開放されています。 Zhipu AIチームが望んでいるのは、オープンソースモデルがクローズドソースモデルのエージェント能力に到達するか、それを超えることです。つまり、エージェントは、「ツール呼び出し、コード実行、ゲーム、データベース操作、ナレッジグラフの検索と推論、オペレーティングシステム」などの複雑なシナリオに対して、国内の大規模モデルのネイティブサポートを有効にします。### **1.5B / 3Bが同時にリリースされ、携帯電話が動作可能**お使いの携帯電話でChatGLMを実行したいですか? わかりました!今回、ChatGLM3は、1.5Bと3Bの2つのパラメータを持つ、携帯電話に展開できる端末テストモデルも発売しました。Vivo、Xiaomi、Samsung、車載プラットフォームなど、さまざまな携帯電話をサポートでき、モバイルプラットフォーム上のCPUチップの推論もサポートし、最大20トークン/秒の速度で対応します。精度の面では、公開ベンチマーク評価では1.5Bと3Bモデルの性能がChatGLM2-6Bモデルに近いので、ぜひ試してみてください! ## **新世代の「Zhipu Qingyan」が本格的に発売** ChatGPTが強力なGPT-4モデルを背後に持っているように、Zhipu AIチームの生成AIアシスタント「Zhipu Qingyan」もChatGLM3の恩恵を受けています。このチームの生放送デモンストレーションの後、機能は直接開始されました、そして主なものは誠実さです!テストアドレス:### **コードインタプリタ**ChatGPT の最も人気のあるプラグインの 1 つである Advanced Data Analysis (旧 Code Interpreter) は、自然言語入力に基づいてより数学的思考で問題を分析し、同時に適切なコードを生成できます。今回、新しくアップグレードされたChatGLM3のサポートにより、「Zhipu Qingyan」は中国で最初の高度なデータ分析機能を備えた大規模モデル製品となり、画像処理、数学的コンピューティング、データ分析、その他の使用シナリオをサポートできます。理工系男性のロマンは「志普青燕」にしか理解できないかもしれません。CEOのZhang Pengは「赤いハート」の覆しを描くためにライブパフォーマンスを行いましたが、もう一度試してみたところ、結果は数秒で出ました。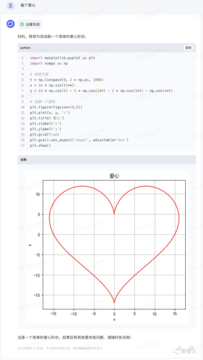 同様に、アップグレードされたChatGLM3もデータ分析に非常に優れています。 いくつかの分析の後、フィールドの長さに基づいて長さ分布のヒストグラムを描画できます。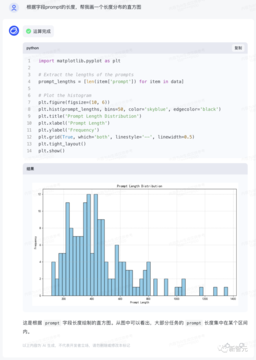 ### **検索機能の強化**WebGLMの大規模モデル機能の追加により、「Zhipu Qingyan」は、インターネット上の最新情報に基づいて質問への回答を要約し、参照リンクを添付して検索する機能も備えています。例えば、iPhone 15は最近値下げの波が押し寄せていますが、具体的な変動はどのくらいなのでしょうか?「Zhipu Qingyan」の答えは悪くありません!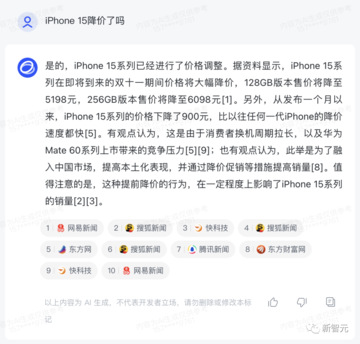 ### **グラフィックの理解**CogVLMモデルは、Zhipu Qingyanの中国語の画像とテキストの理解能力を向上させ、GPT-4Vに近い画像理解能力を獲得します。さまざまな種類の視覚的な質問に答えることができ、複雑なオブジェクトの検出、ラベル付け、および完全な自動データ注釈を完了できます。例として、CogVLMに写真に写っている人の数を特定させます。  少し難しくして、3つのオレンジを一緒に描いてみると、数量を正確に特定することもできます。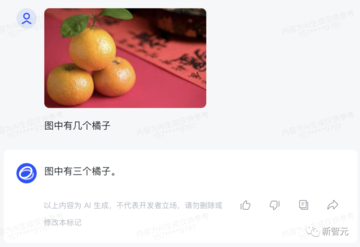  ネイマール、メッシ、ロナウド、CogVLMも明白です。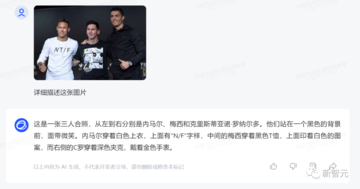 2つのリンゴと1つのリンゴが追加される視覚数学の問題の場合、CogVLMも正しく行うことができます。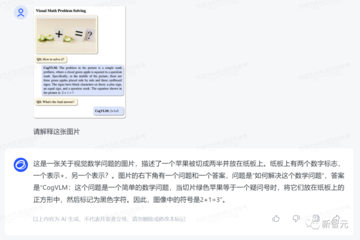 ## **GLM vs GPT:OpenAIのフルラインの製品ラインをベンチマーク! ** チャットと会話のアプリケーションであるChatGPT、コード生成プラグインのCode InterpreterからDALL· E 3、そしてビジュアルマルチモーダルモデルGPT-4Vまで、OpenAIは現在、製品アーキテクチャの完全なセットを持っています。中国を振り返ってみると、最も包括的な製品カバレッジを実現できる唯一の企業はZhipu AIです。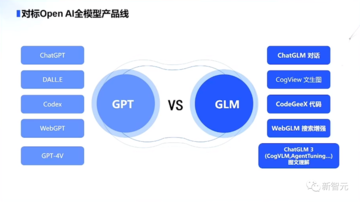 ### **会話:ChatGPTと チャットGLM**人気のフライドチキンChatGPTの紹介については、これ以上言う必要はありません。今年の初めに、Zhipu AIチームは、1,000億レベルの対話モデルであるChatGLMもリリースしました。ChatGPTの設計アイデアを利用して、開発者は1,000億のベースモデルGLM-130Bにコードの事前トレーニングを注入しました。実際、早くも2022年にZhipu AIはGLM-130Bを研究コミュニティと業界に公開し、この研究はACL2022とICLR 2023でも受け入れられました。ChatGLM-6B モデルと ChatGLM-130B モデルはどちらも、教師あり微調整 (SFT)、フィードバック ブートストラップ、および人間フィードバック強化学習 (RLHF) を使用して、1T トークンを含む中国語と英語のコーパスでトレーニングされました。 ChatGLM モデルは、人間の好みに合った回答を生成することができます。 量子化技術と組み合わせることで、ユーザーはコンシューマーグレードのグラフィックスカードにローカルに展開し(INT4量子化レベルでは6GBのビデオメモリのみが必要です)、GLMモデルに基づいてラップトップで独自のChatGLMを実行できます。3月14日、Zhipu AIはChatGLM-6Bをコミュニティにオープンソース化し、中国語の自然言語、中国語の対話、中国語のQ&A、推論タスクの第三者評価で1位を獲得しました。同時に、ChatGLM-6Bをベースにした何百ものプロジェクトやアプリケーションが誕生しました。大規模モデルのオープンソースコミュニティの発展をさらに促進するために、Zhipu AIは6月にChatGLM2をリリースし、6B、12B、32B、66B、130Bの異なるサイズを含む1000億ベースの対話モデルをアップグレードしてオープンソース化し、機能を向上させ、シナリオを充実させました。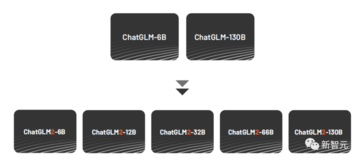 2023年6月25日現在、ChatGLM2はC-リストランク0、ChatGLM2-6Bランク6位で、中国のリストで1位にランクされています。 第1世代モデルと比較して、ChatGLM 2はMMLU、C-、GSM8Kでそれぞれ16%、36%、280%の改善を達成しています。わずか数か月で、ChatGLM-6BとChatGLM2-6Bが広く使用されていることは言及する価値があります。現在、合計50,000+の星がGitHubで収集されています。 さらに、Hugging Faceには10,000,000+のダウンロードがあり、4週間のトレンドで1位にランクされています。 ChatGLM-6B: ChatGLM2-6B:### **検索の機能強化:WebGPTと WebGLM(英語)**大規模モデルの「錯覚」の問題を解決するために、一般的な解決策は、検索エンジンの知識を組み合わせ、大規模モデルに「検索強化」を実行させることです。早くも2021年には、OpenAIはGPT-3-WebGPTに基づいて検索結果を集計できるモデルを微調整しました。WebGPTは、人間の検索行動をモデル化し、Webページ内を検索して関連する回答を見つけ、引用元を提供することで、出力結果を追跡できるようにします。最も重要なのは、オープンドメインの長いQ&Aで優れた結果を達成したことです。この考えのもと、ChatGLMの100億パラメータの微調整に基づくモデルであるChatGLMの「ネットワーク版」モデルであるWebGLMが誕生し、ネットワーク検索がメインとなっています。 住所:たとえば、空が青い理由を知りたいとき。 WebGLMは、オンラインですぐに回答を提供し、モデルの回答の信頼性を高めるためのリンクが含まれています。 アーキテクチャ的には、WebGLM 検索拡張システムには、retriever、generator、scorer という 3 つの重要なコンポーネントが含まれています。LLMベースのレトリーバーは、粒度の粗いネットワーク検索(探索、取得、抽出)と、きめ細かな蒸留検索の2つの段階に分かれています。レトリーバーの全工程において、主にWebページを取得する処理に時間が消費されるため、WebGLMでは並列非同期技術を用いて効率化を図っています。ブートストラップジェネレータはコアであり、レトリーバーから取得したリファレンスページから質問に対する高品質の回答を生成する役割を担います。大規模なモデルのコンテキスト推論機能を使用して高品質の QA データセットを生成し、トレーニング用に高品質のサブセットを除外するための修正および選択戦略を設計します。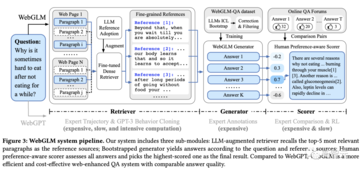 最終的な評価者は、人間の好みに合わせるために、RLHFを通じてWebGLMが生成した回答を採点するために使用されます。実験結果は、WebGLMがより正確な結果を提供し、Q&Aタスクを効率的に完了できることを示しています。 さらに、100億個のパラメータのパフォーマンスで1750億個のパラメータを持つWebGPTに近づくことができます。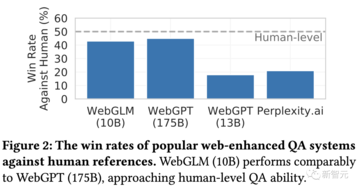 現在、この研究はKDD 2023に採択されており、Zhipu AIチームも機能とデータセットをオープンソース化しています。 プロジェクトの住所:### **画像とテキストの理解:GPT-4Vと CogVLM**今年9月、OpenAIはGPT-4の驚くべきマルチモーダル機能の禁止を正式に解除しました。これに支えられたGPT-4Vは、画像を理解する能力が高く、任意に混合されたマルチモーダル入力を処理することができます。例えば、写真の料理が麻婆豆腐だとはわからず、それを作るための材料さえ与えることができます。 10月、Zhipuは、NLPタスクのパフォーマンスを犠牲にすることなく、視覚言語機能の深い統合を実現できる新しい視覚言語基本モデルであるCogVLMをオープンソース化しました。一般的な浅い融合法とは異なり、CogVLMは、トレーニング可能なビジョンエキスパートモジュールをアテンションメカニズムとフィードフォワードニューラルネットワーク層に組み込んでいます。この設計により、画像とテキストの特徴の深い位置合わせが実現され、事前トレーニング済みの言語モデルと画像エンコーダーの違いが効果的に補正されます。現在、CogVLM-17Bは、マルチモーダル権威学術リストで最初の総合スコアを獲得したモデルであり、14のデータセットでSOTAまたは2位の結果を達成しています。NoCaps、Flicker30k captioning、RefCOCO、RefCOCO+、RefCOCOg、Visual7W、GQA、ScienceQA、VizWiz-VQA、TDIUC など、10 の権威あるクロスモーダルベンチマークで最高の (SOTA) パフォーマンスを達成しています。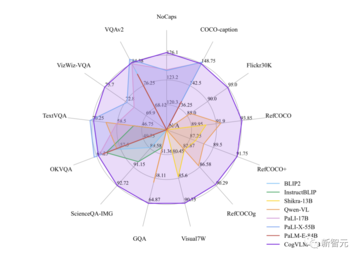 CogVLMの核となる考え方は「ビジュアルファースト」です。従来のマルチモーダルモデルでは、通常、画像特徴量をテキスト特徴量の入力空間に直接位置合わせし、画像特徴量のエンコーダーは通常小さく、この場合、画像はテキストの「属国」と見なすことができ、効果は当然制限されます。一方、CogVLMは、マルチモーダルモデルにおける視覚的理解を優先し、5Bパラメータのビジョンエンコーダと6Bパラメータのビジョンエキスパートモジュールを使用して、7Bパラメータのテキスト量よりもさらに多い合計11Bパラメータで画像の特徴をモデル化します。いくつかのテストでは、CogVLMはGPT-4Vを凌駕しました。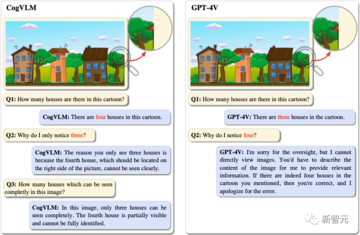 写真には4軒の家があり、3軒は丸見えで、1軒は拡大した場合にのみ見ることができます。CogVLMはこれら4つのハウスを正確に識別できますが、GPT-4Vは3つのハウスしか識別できません。この質問では、テキスト付きの画像がテストされます。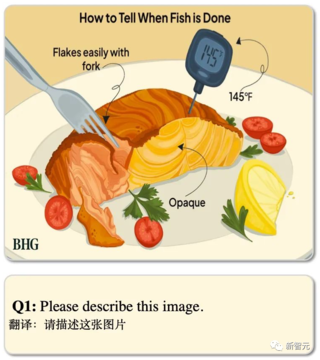 CogVLMは、シーンとそれに対応するテキストを忠実に記述します。 ### **ウェンシェン図:DALL· E 対 コグビュー**OpenAI の最も強力な Wensheng グラフ モデルは DALL· E 3も。 対照的に、Zhipu AIチームは、Transformerベースのテキストから画像へのユニバーサル事前トレーニング済みモデルであるCogViewを立ち上げました。 住所:CogViewの全体的な考え方は、テキスト特徴量と画像トークン特徴量をつなぎ合わせることによって自己回帰学習を実行することです。 最後に、テキストトークン特徴のみが入力され、モデルは画像トークンを連続的に生成できます。具体的には、まず「かわいい子猫のアバター」というテキストをトークンに変換し、ここではSentencePieceモデルを使用します。次に、猫の画像が入力され、画像部分が離散自動デコーダーを介してトークンに変換されます。次に、テキストと画像トークンの特徴をつなぎ合わせ、TransformerアーキテクチャのGPTモデルに入力して、画像の生成を学習します。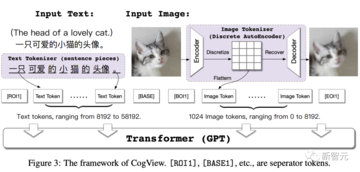 最後に、トレーニングが完了すると、モデルはキャプション スコアを計算して生成された結果を並べ替え、テキストから画像への生成タスク中に最も一致する結果を選択します。Comparison of DALL· Eおよび一般的なGANスキームでは、CogViewの結果が大幅に改善されました。2022年、研究者らはWenshengグラフモデルCogView2を再びアップグレードし、その効果をDALL· E2。 住所:CogViewと比較して、CogView2のアーキテクチャは、画像生成に階層型トランスフォーマーと並列自己回帰モードを採用しています。この論文では、研究者らは60億パラメータのTransformerモデルであるCross-Modal General Language Model(CogLM)を事前にトレーニングし、高速な超解像を実現するために微調整しました。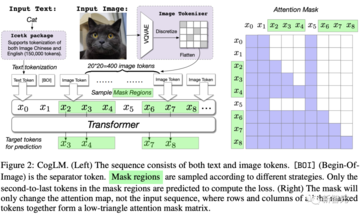 実験結果は、DALL· E2 には、CogView2 で結果を生成できるという利点もあり、画像のインタラクティブなテキストガイド付き編集もサポートできます。同年11月には、CogView2モデルをベースにしたテキストから動画への生成モデル「CogVideo」を構築しました。モデルアーキテクチャは2つのモジュールに分かれており、最初の部分はCogView2に基づいており、テキストから画像のフレームを数フレーム生成します。 2番目の部分は、双方向アテンションモデルに基づいて画像を補間し、より高いフレームレートで完全なビデオを生成することです。 現在、上記のモデルはすべてオープンソースです。 清華のチームはそんなに率直で誠実ですか?### **コード:コーデックス vs. コードジークス**コード生成の分野では、OpenAIは早くも2021年8月に新しくアップグレードされたCodexをリリースし、Python、Java、Go、Perl、PHP、Ruby、Swift、Type、さらにはShellを含む10以上のプログラミング言語に堪能です。 住所:ユーザーは簡単なプロンプトを入力するだけで、Codexに自然言語でコードを自動的に記述させることができます。Codex は GPT-3 でトレーニングされており、データには数十億行のソース コードが含まれています。 さらに、Codex は GPT-3 の 3 倍以上の長さのコンテキスト情報をサポートできます。 中国のパイオニアとして、Zhipuは2022年9月に130億個のパラメータを持つマルチプログラミング言語のコード生成、翻訳、解釈のための事前学習済みモデルであるCodeGeeXをオープンソース化し、後にKDD 2023(ロングビーチ)で採択されました。 住所:2023年7月、Zhipuは100以上の言語をサポートできる、より強く、より速く、より軽量なCodeGeeX2-6Bをリリースし、その重みは学術研究に完全に開放されています。 プロジェクトの住所:CodeGeeX2 は、新しい ChatGLM2 アーキテクチャに基づいており、コードのオートコンプリート、コード生成、コード変換、ファイル間のコード補完など、さまざまなプログラミング関連のタスク向けに最適化されています。ChatGLM2のアップグレードにより、CodeGeeX2は中国語と英語の入力、および最大シーケンス長8192のサポートを向上させるだけでなく、Python +57%、C++ +71%、Java +54%、Java +83%、Go +56%、Rust +321%など、さまざまなパフォーマンス指標を大幅に改善できます。ヒューマンレビューでは、CodeGeeX2は150億パラメータのStarCoderモデルとOpenAIのCode-Cushman-001モデル(GitHub Copilotが使用するモデル)を総合的に上回りました。また、CodeGeeX2の推論速度は、量子化後の実行に必要なビデオメモリが6GBで済む第1世代のCodeGeeX-13Bよりも高速で、軽量なローカライズ展開に対応しています。現在、CodeGeeXプラグインは、VS Code、IntelliJ IDEA、PyCharm、GoLand、WebStorm、Android Studioなどの主流のIDEでダウンロードして体験できます。 ## **国産大型モデルは完全自社開発** カンファレンスで、Zhipu AIのCEOであるZhang Peng氏は、ラージモデルの初年度はChatGPTがLLMブームを引き起こした年ではなく、GPT-3が誕生した2020年であると、冒頭で自身の意見を述べました。当時、設立して1年が経ったばかりのZhipu AIは、全社の力を総動員して大型モデルでALL化を始めました。Zhipu AIは、大規模なモデル研究に参入した最初の企業の1つとして、十分なエンタープライズサービス能力を蓄積してきました。 オープンソースで「カニを食べた最初の企業」の1つとして、ChatGLM-6Bは発売から4週間以内にHugging faceのトレンドリストのトップに立ち、GitHubで5w+の星を獲得しました。 ChatGLM3のリリースにより、Zhipu AIが構築したフルモデルの製品ラインがより強力になります。2023年、大規模模型業界で戦争が激化する中、Zhipu AIは再び脚光を浴び、新しくアップグレードされたChatGLM3で先行者利益を獲得します。リソース:
清華県ChatGLM3ライブ顔デモンストレーション! マルチモダリティはGPT-4Vに近く、国産のコードインタプリタが来ています
出典:新志源
自社開発の第3世代台座モデル「ChatGLM3」を本日発売!
これは、6月に第2世代モデルが発売されて以来、Zhipu AIチームによるChatGLMベースモデルの最適化です。
さらに、10月27日に開催された2023 China Computer Conference(CNCC)で、Zhipu AIはChatGLM3-6B(32k)、マルチモーダルCogVLM-17B、エージェントAgentLMもオープンソース化しました。
ChatGLM3シリーズのモデルリリース後、ZhipuはOpenAIのフルモデル製品ラインをベンチマークした中国で唯一の企業となった。
このモデルは完全に自社開発されており、国産チップに適応し、より強力なパフォーマンスとよりオープンソースのエコシステムを備えています。
大規模模型研究に参入した最初の企業として、Zhipu AIが最初に論文を提出しました!
さらに、Zhipu AIは今年、美団、蟻、アリババ、テンセントなど、合計25億元以上の資金調達を完了しました。 豪華な投資家のリストはすべて、Zhipu AIに対する業界の強い信頼を示しています。
GPT-4Vの技術向上を目指して
現在、マルチモーダルビジョンモデルGPT-4Vは、強力な画像認識能力を示しています。
同時に、GPT-4Vを目指して、Zhipu AIは今回、ChatGLM3の他の機能も繰り返しアップグレードしました。 その中で、マルチモーダル理解モデルCogVLMは、10+の国際標準グラフィックおよびテキスト評価データセットSOTAを理解し、更新しようとすることができます。 現在、CogVLM-17Bはオープンソース化されています。
Code Interpreterは、ユーザーのニーズに応じてコードを生成および実行し、データ分析やファイル処理などの複雑なタスクを自動的に完了できます。
Web検索はWebGLMを強化し、質問に応じてインターネット上の関連情報を自動的に検索し、回答時に参照文献や記事へのリンクを提供します。
さらに、ChatGLM3 のセマンティックおよび論理機能も大幅に強化されています。
バージョン6Bダイレクトオープンソース
特筆すべきは、ChatGLM3がリリースされると、Zhipu AIが6Bパラメータモデルをコミュニティに直接オープンソース化したことです。
評価結果によると、ChatGLM2と比較し、同じサイズの国内モデルと比較して、ChatGLM3-6Bは44の中国語と英語の公開データセットテストのうち9つで1位でした。
MMLUは36%、Cは33%、GSM8Kは179%、BBHは126%増加しました。
オープンソースの32kバージョンであるChatGLM3-6B-32Kは、LongBenchで最高のパフォーマンスを発揮します。
また、現在の推論フレームワークを同じハードウェア・モデル条件でより効率的にする最新の「効率的動的推論+映像メモリ最適化技術」です。
バークレー大学が立ち上げたvLLMや最新バージョンのHugging Face TGIと比較すると、推論速度は2〜3倍、推論コストは1倍に削減され、1000トークンあたり0.5ポイントしかなく、最も低いコストです。
自社開発のAgentTuning、エージェントの能力発動
さらに驚くべきことに、ChatGLM3 には新しいエージェント機能も搭載されています。
Zhipu AIは、大規模なモデルがAPIを介して外部ツールとより適切に通信し、エージェントを介して大規模なモデルの相互作用を実現できることを期待しています。
自社開発のAgentTuningテクノロジーを統合することで、特にインテリジェントな計画と実行の面で、モデルのインテリジェントエージェント機能を活性化することができ、ChatGLM 2よりも1000%高くなっています。
最新のAgentBenchでは、ChatGLM3-turboはGPT-3.5に近いです。
同時に、AgentLMはオープンソースコミュニティにも開放されています。 Zhipu AIチームが望んでいるのは、オープンソースモデルがクローズドソースモデルのエージェント能力に到達するか、それを超えることです。
つまり、エージェントは、「ツール呼び出し、コード実行、ゲーム、データベース操作、ナレッジグラフの検索と推論、オペレーティングシステム」などの複雑なシナリオに対して、国内の大規模モデルのネイティブサポートを有効にします。
1.5B / 3Bが同時にリリースされ、携帯電話が動作可能
お使いの携帯電話でChatGLMを実行したいですか? わかりました!
今回、ChatGLM3は、1.5Bと3Bの2つのパラメータを持つ、携帯電話に展開できる端末テストモデルも発売しました。
Vivo、Xiaomi、Samsung、車載プラットフォームなど、さまざまな携帯電話をサポートでき、モバイルプラットフォーム上のCPUチップの推論もサポートし、最大20トークン/秒の速度で対応します。
精度の面では、公開ベンチマーク評価では1.5Bと3Bモデルの性能がChatGLM2-6Bモデルに近いので、ぜひ試してみてください!
新世代の「Zhipu Qingyan」が本格的に発売
ChatGPTが強力なGPT-4モデルを背後に持っているように、Zhipu AIチームの生成AIアシスタント「Zhipu Qingyan」もChatGLM3の恩恵を受けています。
このチームの生放送デモンストレーションの後、機能は直接開始されました、そして主なものは誠実さです!
テストアドレス:
コードインタプリタ
ChatGPT の最も人気のあるプラグインの 1 つである Advanced Data Analysis (旧 Code Interpreter) は、自然言語入力に基づいてより数学的思考で問題を分析し、同時に適切なコードを生成できます。
今回、新しくアップグレードされたChatGLM3のサポートにより、「Zhipu Qingyan」は中国で最初の高度なデータ分析機能を備えた大規模モデル製品となり、画像処理、数学的コンピューティング、データ分析、その他の使用シナリオをサポートできます。
理工系男性のロマンは「志普青燕」にしか理解できないかもしれません。
CEOのZhang Pengは「赤いハート」の覆しを描くためにライブパフォーマンスを行いましたが、もう一度試してみたところ、結果は数秒で出ました。
WebGLMの大規模モデル機能の追加により、「Zhipu Qingyan」は、インターネット上の最新情報に基づいて質問への回答を要約し、参照リンクを添付して検索する機能も備えています。
例えば、iPhone 15は最近値下げの波が押し寄せていますが、具体的な変動はどのくらいなのでしょうか?
「Zhipu Qingyan」の答えは悪くありません!
CogVLMモデルは、Zhipu Qingyanの中国語の画像とテキストの理解能力を向上させ、GPT-4Vに近い画像理解能力を獲得します。
さまざまな種類の視覚的な質問に答えることができ、複雑なオブジェクトの検出、ラベル付け、および完全な自動データ注釈を完了できます。
例として、CogVLMに写真に写っている人の数を特定させます。
**GLM vs GPT:OpenAIのフルラインの製品ラインをベンチマーク! **
チャットと会話のアプリケーションであるChatGPT、コード生成プラグインのCode InterpreterからDALL· E 3、そしてビジュアルマルチモーダルモデルGPT-4Vまで、OpenAIは現在、製品アーキテクチャの完全なセットを持っています。
中国を振り返ってみると、最も包括的な製品カバレッジを実現できる唯一の企業はZhipu AIです。
人気のフライドチキンChatGPTの紹介については、これ以上言う必要はありません。
今年の初めに、Zhipu AIチームは、1,000億レベルの対話モデルであるChatGLMもリリースしました。
ChatGPTの設計アイデアを利用して、開発者は1,000億のベースモデルGLM-130Bにコードの事前トレーニングを注入しました。
実際、早くも2022年にZhipu AIはGLM-130Bを研究コミュニティと業界に公開し、この研究はACL2022とICLR 2023でも受け入れられました。
ChatGLM-6B モデルと ChatGLM-130B モデルはどちらも、教師あり微調整 (SFT)、フィードバック ブートストラップ、および人間フィードバック強化学習 (RLHF) を使用して、1T トークンを含む中国語と英語のコーパスでトレーニングされました。
3月14日、Zhipu AIはChatGLM-6Bをコミュニティにオープンソース化し、中国語の自然言語、中国語の対話、中国語のQ&A、推論タスクの第三者評価で1位を獲得しました。
同時に、ChatGLM-6Bをベースにした何百ものプロジェクトやアプリケーションが誕生しました。
大規模モデルのオープンソースコミュニティの発展をさらに促進するために、Zhipu AIは6月にChatGLM2をリリースし、6B、12B、32B、66B、130Bの異なるサイズを含む1000億ベースの対話モデルをアップグレードしてオープンソース化し、機能を向上させ、シナリオを充実させました。
わずか数か月で、ChatGLM-6BとChatGLM2-6Bが広く使用されていることは言及する価値があります。
現在、合計50,000+の星がGitHubで収集されています。 さらに、Hugging Faceには10,000,000+のダウンロードがあり、4週間のトレンドで1位にランクされています。
検索の機能強化:WebGPTと WebGLM(英語)
大規模モデルの「錯覚」の問題を解決するために、一般的な解決策は、検索エンジンの知識を組み合わせ、大規模モデルに「検索強化」を実行させることです。
早くも2021年には、OpenAIはGPT-3-WebGPTに基づいて検索結果を集計できるモデルを微調整しました。
WebGPTは、人間の検索行動をモデル化し、Webページ内を検索して関連する回答を見つけ、引用元を提供することで、出力結果を追跡できるようにします。
最も重要なのは、オープンドメインの長いQ&Aで優れた結果を達成したことです。
この考えのもと、ChatGLMの100億パラメータの微調整に基づくモデルであるChatGLMの「ネットワーク版」モデルであるWebGLMが誕生し、ネットワーク検索がメインとなっています。
たとえば、空が青い理由を知りたいとき。 WebGLMは、オンラインですぐに回答を提供し、モデルの回答の信頼性を高めるためのリンクが含まれています。
LLMベースのレトリーバーは、粒度の粗いネットワーク検索(探索、取得、抽出)と、きめ細かな蒸留検索の2つの段階に分かれています。
レトリーバーの全工程において、主にWebページを取得する処理に時間が消費されるため、WebGLMでは並列非同期技術を用いて効率化を図っています。
ブートストラップジェネレータはコアであり、レトリーバーから取得したリファレンスページから質問に対する高品質の回答を生成する役割を担います。
大規模なモデルのコンテキスト推論機能を使用して高品質の QA データセットを生成し、トレーニング用に高品質のサブセットを除外するための修正および選択戦略を設計します。
実験結果は、WebGLMがより正確な結果を提供し、Q&Aタスクを効率的に完了できることを示しています。 さらに、100億個のパラメータのパフォーマンスで1750億個のパラメータを持つWebGPTに近づくことができます。
画像とテキストの理解:GPT-4Vと CogVLM
今年9月、OpenAIはGPT-4の驚くべきマルチモーダル機能の禁止を正式に解除しました。
これに支えられたGPT-4Vは、画像を理解する能力が高く、任意に混合されたマルチモーダル入力を処理することができます。
例えば、写真の料理が麻婆豆腐だとはわからず、それを作るための材料さえ与えることができます。
一般的な浅い融合法とは異なり、CogVLMは、トレーニング可能なビジョンエキスパートモジュールをアテンションメカニズムとフィードフォワードニューラルネットワーク層に組み込んでいます。
この設計により、画像とテキストの特徴の深い位置合わせが実現され、事前トレーニング済みの言語モデルと画像エンコーダーの違いが効果的に補正されます。
現在、CogVLM-17Bは、マルチモーダル権威学術リストで最初の総合スコアを獲得したモデルであり、14のデータセットでSOTAまたは2位の結果を達成しています。
NoCaps、Flicker30k captioning、RefCOCO、RefCOCO+、RefCOCOg、Visual7W、GQA、ScienceQA、VizWiz-VQA、TDIUC など、10 の権威あるクロスモーダルベンチマークで最高の (SOTA) パフォーマンスを達成しています。
従来のマルチモーダルモデルでは、通常、画像特徴量をテキスト特徴量の入力空間に直接位置合わせし、画像特徴量のエンコーダーは通常小さく、この場合、画像はテキストの「属国」と見なすことができ、効果は当然制限されます。
一方、CogVLMは、マルチモーダルモデルにおける視覚的理解を優先し、5Bパラメータのビジョンエンコーダと6Bパラメータのビジョンエキスパートモジュールを使用して、7Bパラメータのテキスト量よりもさらに多い合計11Bパラメータで画像の特徴をモデル化します。
いくつかのテストでは、CogVLMはGPT-4Vを凌駕しました。
CogVLMはこれら4つのハウスを正確に識別できますが、GPT-4Vは3つのハウスしか識別できません。
この質問では、テキスト付きの画像がテストされます。
OpenAI の最も強力な Wensheng グラフ モデルは DALL· E 3も。
CogViewの全体的な考え方は、テキスト特徴量と画像トークン特徴量をつなぎ合わせることによって自己回帰学習を実行することです。 最後に、テキストトークン特徴のみが入力され、モデルは画像トークンを連続的に生成できます。
具体的には、まず「かわいい子猫のアバター」というテキストをトークンに変換し、ここではSentencePieceモデルを使用します。
次に、猫の画像が入力され、画像部分が離散自動デコーダーを介してトークンに変換されます。
次に、テキストと画像トークンの特徴をつなぎ合わせ、TransformerアーキテクチャのGPTモデルに入力して、画像の生成を学習します。
Comparison of DALL· Eおよび一般的なGANスキームでは、CogViewの結果が大幅に改善されました。
2022年、研究者らはWenshengグラフモデルCogView2を再びアップグレードし、その効果をDALL· E2。
CogViewと比較して、CogView2のアーキテクチャは、画像生成に階層型トランスフォーマーと並列自己回帰モードを採用しています。
この論文では、研究者らは60億パラメータのTransformerモデルであるCross-Modal General Language Model(CogLM)を事前にトレーニングし、高速な超解像を実現するために微調整しました。
同年11月には、CogView2モデルをベースにしたテキストから動画への生成モデル「CogVideo」を構築しました。
モデルアーキテクチャは2つのモジュールに分かれており、最初の部分はCogView2に基づいており、テキストから画像のフレームを数フレーム生成します。 2番目の部分は、双方向アテンションモデルに基づいて画像を補間し、より高いフレームレートで完全なビデオを生成することです。
コード:コーデックス vs. コードジークス
コード生成の分野では、OpenAIは早くも2021年8月に新しくアップグレードされたCodexをリリースし、Python、Java、Go、Perl、PHP、Ruby、Swift、Type、さらにはShellを含む10以上のプログラミング言語に堪能です。
ユーザーは簡単なプロンプトを入力するだけで、Codexに自然言語でコードを自動的に記述させることができます。
Codex は GPT-3 でトレーニングされており、データには数十億行のソース コードが含まれています。 さらに、Codex は GPT-3 の 3 倍以上の長さのコンテキスト情報をサポートできます。
2023年7月、Zhipuは100以上の言語をサポートできる、より強く、より速く、より軽量なCodeGeeX2-6Bをリリースし、その重みは学術研究に完全に開放されています。
CodeGeeX2 は、新しい ChatGLM2 アーキテクチャに基づいており、コードのオートコンプリート、コード生成、コード変換、ファイル間のコード補完など、さまざまなプログラミング関連のタスク向けに最適化されています。
ChatGLM2のアップグレードにより、CodeGeeX2は中国語と英語の入力、および最大シーケンス長8192のサポートを向上させるだけでなく、Python +57%、C++ +71%、Java +54%、Java +83%、Go +56%、Rust +321%など、さまざまなパフォーマンス指標を大幅に改善できます。
ヒューマンレビューでは、CodeGeeX2は150億パラメータのStarCoderモデルとOpenAIのCode-Cushman-001モデル(GitHub Copilotが使用するモデル)を総合的に上回りました。
また、CodeGeeX2の推論速度は、量子化後の実行に必要なビデオメモリが6GBで済む第1世代のCodeGeeX-13Bよりも高速で、軽量なローカライズ展開に対応しています。
現在、CodeGeeXプラグインは、VS Code、IntelliJ IDEA、PyCharm、GoLand、WebStorm、Android Studioなどの主流のIDEでダウンロードして体験できます。
国産大型モデルは完全自社開発
カンファレンスで、Zhipu AIのCEOであるZhang Peng氏は、ラージモデルの初年度はChatGPTがLLMブームを引き起こした年ではなく、GPT-3が誕生した2020年であると、冒頭で自身の意見を述べました。
当時、設立して1年が経ったばかりのZhipu AIは、全社の力を総動員して大型モデルでALL化を始めました。
Zhipu AIは、大規模なモデル研究に参入した最初の企業の1つとして、十分なエンタープライズサービス能力を蓄積してきました。 オープンソースで「カニを食べた最初の企業」の1つとして、ChatGLM-6Bは発売から4週間以内にHugging faceのトレンドリストのトップに立ち、GitHubで5w+の星を獲得しました。
2023年、大規模模型業界で戦争が激化する中、Zhipu AIは再び脚光を浴び、新しくアップグレードされたChatGLM3で先行者利益を獲得します。
リソース: