原文来源:量子位>GPT-4VはSiriの終わりの始まりです。 画像ソース: Unbounded AIによって生成ある研究では、次のことがわかりました。GPT-4Vは、トレーニングなしでも人間のようにスマートフォンと直接対話し、指定されたさまざまなコマンドを完了することができます。たとえば、**50ドルから100ドルの予算内でミルク泡立て器を購入するように依頼します**。ショッピングプログラム(Amazon)の選択を段階的に完了して開き、検索バーをクリックして「ミルク泡立て器」と入力し、フィルター機能を見つけ、予算範囲を選択し、製品をクリックして注文を完了し、合計9つのアクションを実行できます。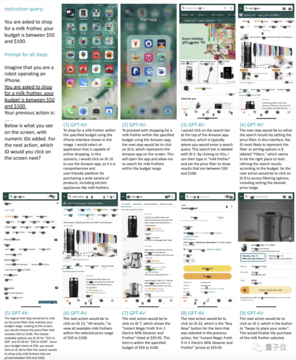 テストによると、GPT-4VはiPhoneで同様のタスクを完了する際に75%の成功率を持っています。したがって、Siriが徐々に役に立たなくなると嘆く人もいます(SiriよりもiPhoneをよく理解しています) 誰かが直接手を振ったことを誰が知っていましたか?そもそもSiriはそんなに強くなかった。 (ドッグヘッド) また、何人かの人々は叫びました:> インテリジェントな音声対話の時代が始まりました。 私たちの携帯電話は、純粋なディスプレイデバイスになろうとしているのかもしれません。 🐂🍺 ほんとですか。## **GPT-4Vゼロサンプル操作iPhone**この研究は、カリフォルニア大学サンディエゴ校、マイクロソフトなどから行われました。それ自体は、GPT-4VベースのエージェントであるMM-Navigatorの開発であり、スマートフォンのユーザーインターフェイスでナビゲーションタスクを実行するために使用されます。### **実験のセットアップ**各タイムステップで、MM-Navigatorはスクリーンショットを取得します。マルチモーダルモデルとして、GPT-4Vは画像とテキストを入力として受け入れ、テキスト出力を生成します。ここでは、スクリーンショット情報をステップバイステップで読み取り、操作するステップを出力します。さて、質問は:特定の画面でクリックする必要がある正確な位置座標をモデルに合理的に計算させる方法(GPT-4Vはおおよその位置しか提供できません)。著者が提示した解決策は非常にシンプルで、OCRツールとIconNetを使用して、**特定の画面のUI要素を検出し、それらを異なる番号でマーク**します。 このように、GPT-4Vはスクリーンショットを直視するだけで、どの数字を指摘するかを示すことができます。### **2つの適性検査**テストは最初にiPhoneで行われました。携帯電話をうまく操作するには、GPT-4Vがさまざまな種類の画面を理解する必要があります。1つはセマンティック推論で、画面上の入力を理解し、与えられた指示を完了するために必要なアクションを明確にします。1つは、各アクションを実行する必要がある正確な場所(つまり、その時点での番号)を示す機能です。そこで、著者らは、それらを区別するために2組の検定を開発した。**1. 想定されるアクションの説明**特定の座標ではなく、やるべきことだけを出力します。このタスクでは、GPT-4Vは指示を理解し、90.9%の精度で操作手順を提供します。たとえば、Safariブラウザの下のスクリーンショットでは、ユーザーは新しいタブを開きたいのですが、左下隅の+記号がグレーアウトされていますが、どうすればよいですか?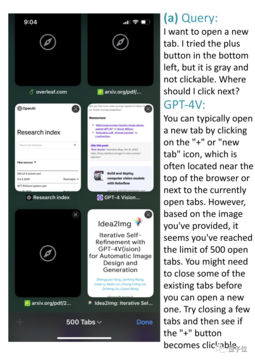 GPT-4V回答:> 通常はこれで問題ありませんが、スクリーンショットから判断すると、500タブの制限に達したようで、新しいタブを開くには、既存のタブのいくつかを閉じて、+記号をクリックできるかどうかを確認する必要があります。 >絵の理解度を見ると、とても良いですよ~ その他の例については、紙をめくることができます。**2. ローカライズされたアクションの実行**GPT-4Vに、これらの「紙の上の言葉」を具体的な行動(つまり、2回目のテストミッション)に変えるよう求めたところ、その正解率は74.5%に低下しました。繰り返しになりますが、上記の例では、独自の指示に従い、数字の 9 をクリックしてタブを閉じるなど、正しい操作番号を指定できます。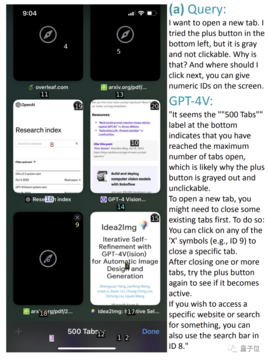 しかし、下の画像に示すように、建物を認識できるアプリを探すように求められたときに、ChatGPTの使用を正確に指摘することができますが、間違った数字「15」(「5」であるはず)が表示されます。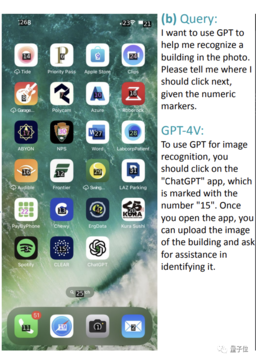 スクリーンショット自体が対応する位置でマークされていないため、エラーもあります。例えば、下の写真からステルスモードをONにすると,Wi-Fiが「11」の位置にあるので、全然一致しません。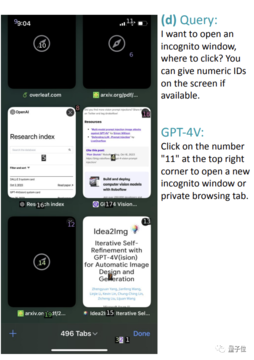 さらに、この単純なシングルステップのタスクに加えて、GPT-4Vはトレーニングなしで「エアレーターを買う」などの複雑な指示を処理できることもテストでわかりました。このプロセスでは、GPT-4Vが各ステップで何をすべきか、および対応する数値座標を詳細にリストアップしていることがわかります。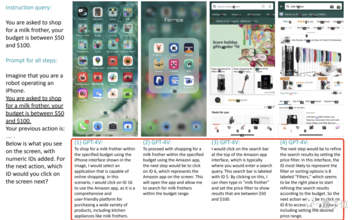 最後に、Androidでのテストがあります。全体として、Llama 2、PaLM 2、ChatGPT などの他のモデルよりも大幅に優れたパフォーマンスを発揮します。インストールやショッピングなどのタスクの実行に関する全体的なパフォーマンス スコアの最高値は 52.96% で、これらのベースライン モデルの最高スコアは 39.6% でした。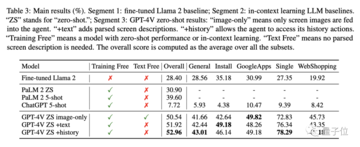 実験全体において、GPT-4Vのようなマルチモーダルモデルが、目に見えないシーンに直接能力を伝達できることを証明し、携帯電話でのインタラクションに大きな可能性を秘めていることを証明したことが最大の意義です。この研究を読んだ後、ネチズンは2つのポイントも提唱したことに言及する価値があります。1つ目は、タスク実行の成功をどのように定義するかです。たとえば、手指消毒剤の詰め替え用を購入したいのに、1 つのバッグだけが必要で、さらに 6 つのバッグを購入した場合、それは成功しますか? 第二に、誰もが早々に興奮するわけにはいかず、この技術を本当に商業化したいのであれば、まだ進歩の余地がたくさんあります。というのも、正解率が最大95%のSiriは、非常に貧弱だと不満を言われることが多いからです。 ## **チーム紹介**この研究には 12 人の著者がおり、そのほとんどが Microsoft の研究者です。 1対2。カリフォルニア大学サンディエゴ校の博士課程の学生であるAn Yan氏と、中国科学技術大学で学士号、ロチェスター大学で博士号を取得したMicrosoftの上級研究員であるZhengyuan Yang氏です。参考リンク: [1] [2]
GPT-4Vは、トレーニングなしで電話を「操作」して任意のコマンドを完了できます
原文来源:量子位
ある研究では、次のことがわかりました。
GPT-4Vは、トレーニングなしでも人間のようにスマートフォンと直接対話し、指定されたさまざまなコマンドを完了することができます。
たとえば、50ドルから100ドルの予算内でミルク泡立て器を購入するように依頼します。
ショッピングプログラム(Amazon)の選択を段階的に完了して開き、検索バーをクリックして「ミルク泡立て器」と入力し、フィルター機能を見つけ、予算範囲を選択し、製品をクリックして注文を完了し、合計9つのアクションを実行できます。
したがって、Siriが徐々に役に立たなくなると嘆く人もいます(SiriよりもiPhoneをよく理解しています)
そもそもSiriはそんなに強くなかった。 (ドッグヘッド)
GPT-4Vゼロサンプル操作iPhone
この研究は、カリフォルニア大学サンディエゴ校、マイクロソフトなどから行われました。
それ自体は、GPT-4VベースのエージェントであるMM-Navigatorの開発であり、スマートフォンのユーザーインターフェイスでナビゲーションタスクを実行するために使用されます。
実験のセットアップ
各タイムステップで、MM-Navigatorはスクリーンショットを取得します。
マルチモーダルモデルとして、GPT-4Vは画像とテキストを入力として受け入れ、テキスト出力を生成します。
ここでは、スクリーンショット情報をステップバイステップで読み取り、操作するステップを出力します。
さて、質問は:
特定の画面でクリックする必要がある正確な位置座標をモデルに合理的に計算させる方法(GPT-4Vはおおよその位置しか提供できません)。
著者が提示した解決策は非常にシンプルで、OCRツールとIconNetを使用して、特定の画面のUI要素を検出し、それらを異なる番号でマークします。
2つの適性検査
テストは最初にiPhoneで行われました。
携帯電話をうまく操作するには、GPT-4Vがさまざまな種類の画面を理解する必要があります。
1つはセマンティック推論で、画面上の入力を理解し、与えられた指示を完了するために必要なアクションを明確にします。
1つは、各アクションを実行する必要がある正確な場所(つまり、その時点での番号)を示す機能です。
そこで、著者らは、それらを区別するために2組の検定を開発した。
1. 想定されるアクションの説明
特定の座標ではなく、やるべきことだけを出力します。
このタスクでは、GPT-4Vは指示を理解し、90.9%の精度で操作手順を提供します。
たとえば、Safariブラウザの下のスクリーンショットでは、ユーザーは新しいタブを開きたいのですが、左下隅の+記号がグレーアウトされていますが、どうすればよいですか?
絵の理解度を見ると、とても良いですよ~ その他の例については、紙をめくることができます。
2. ローカライズされたアクションの実行
GPT-4Vに、これらの「紙の上の言葉」を具体的な行動(つまり、2回目のテストミッション)に変えるよう求めたところ、その正解率は74.5%に低下しました。
繰り返しになりますが、上記の例では、独自の指示に従い、数字の 9 をクリックしてタブを閉じるなど、正しい操作番号を指定できます。
例えば、下の写真からステルスモードをONにすると,Wi-Fiが「11」の位置にあるので、全然一致しません。
このプロセスでは、GPT-4Vが各ステップで何をすべきか、および対応する数値座標を詳細にリストアップしていることがわかります。
全体として、Llama 2、PaLM 2、ChatGPT などの他のモデルよりも大幅に優れたパフォーマンスを発揮します。
インストールやショッピングなどのタスクの実行に関する全体的なパフォーマンス スコアの最高値は 52.96% で、これらのベースライン モデルの最高スコアは 39.6% でした。
この研究を読んだ後、ネチズンは2つのポイントも提唱したことに言及する価値があります。
1つ目は、タスク実行の成功をどのように定義するかです。
たとえば、手指消毒剤の詰め替え用を購入したいのに、1 つのバッグだけが必要で、さらに 6 つのバッグを購入した場合、それは成功しますか?
というのも、正解率が最大95%のSiriは、非常に貧弱だと不満を言われることが多いからです。
チーム紹介
この研究には 12 人の著者がおり、そのほとんどが Microsoft の研究者です。
カリフォルニア大学サンディエゴ校の博士課程の学生であるAn Yan氏と、中国科学技術大学で学士号、ロチェスター大学で博士号を取得したMicrosoftの上級研究員であるZhengyuan Yang氏です。
参考リンク:
[1] [2]