ソース: New Zhiyuan 画像ソース: Unbounded AIによって生成> Q予想の議論は続いており、今日、AIの第一人者であるTian Yuandong氏は、Q\*は初級レベルの数学の問題しか解けず、汎用人工知能も合成データでは実現できない可能性が高いと公言しました。Q\* 予想は、AI コミュニティで引き続き人気があります。Q\* が "Q-learning + A\*" であるかどうか、誰もが推測しています。AIの第一人者である渕人田氏も、「Q\*=Q-learning+A\*」という仮説の蓋然性を詳細に分析しています。同時に、合成データがLLMの未来であると判断する人が増えています。しかし、田元東はこの発言に冷や水を浴びせた。> 私は、汎用人工知能が合成データにズームインするだけで解決できるという主張には部分的に同意しません。 > 検索が強力なのは、環境が適切に設計されていれば、モデルが学習して適応するための新しいパターンが無限に作成されるためです。 > しかし、このような新しいモデルを学習するために何十億ものデータが必要かどうかという問題は未解決のままであり、私たちのアーキテクチャ/学習パラダイムにいくつかの根本的な欠陥があることを示している可能性があります。 > それに対して、人間は「なるほど」という瞬間を通じて新しいパラダイムを発見する方が簡単な場合が多いのです。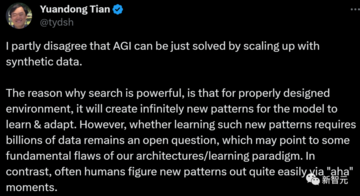 NVIDIAのシニアサイエンティストであるJim Fan氏は、合成データが重要な役割を果たすことに同意していますが、やみくもにスケーリングするだけでは汎用人工知能を実現するのに十分ではありません。 ## **Q\*=Q-learning+A、その可能性はどれくらいですか**Tian Yuandong氏は、OpenGo(AlphaZeroの複製)での過去の経験に基づいて、A\*は値(つまりヒューリスティック)関数Qのみを持つ決定論的MCTSバージョンと見なすことができると述べました。 A*は、特定のアクションの後に状態を評価するのは簡単だが、特定の状態の後にアクションを予測するのが難しいタスクに適しています。 その代表的な例が数学の問題です。対照的に、囲碁は別の話で、次の候補は比較的簡単に予測できますが(局所的な形状を確認するだけで)、盤上の状況を評価するのははるかに困難です。そのため、非常に強力な囲碁ボットもありますが、戦略ネットワークしか利用していません。 LLMの場合、Q(s,a)の評価には事前母集団化のみが必要であるのに対し、予測戦略a = pi(s)は自己回帰サンプリングが必要であり、はるかに遅いため、Q(s,a)を使用することには追加の利点がある可能性があります。 また、デコーダのみを用いる場合には、sのKVキャッシュを複数の演算で共有することができる。数学の問題を解くことですでに大きな飛躍を遂げている伝説のQ\*、これはどれくらいの可能性がありますか?Tian Yuandong氏は、初級レベルの数学の問題が解かれるため、値関数は比較的簡単に設定できるはずだ(たとえば、自然言語の形でターゲット仕様から予測できる)と推測していると述べた。難しい数学の問題を解きたいが、その方法がわからない場合は、このアプローチでは不十分な場合があります。 LeCun氏はTian氏の議論をリツイートし、彼の見解に同意した - "彼はA\*(グラフ内の最短経路の探索)とMCTS(指数関数的に成長する木の探索)の適用性の違いを説明した。 」 LeCun氏のリツイートについて、Tian Yuandong氏は、計画、トランスフォーマー/LLMの理解、効率的な最適化技術など、さまざまなことを行っており、これらの技術を組み合わせることを望んでいると述べました。一部のネチズンは懐疑的な見方を示し、「A\*が有効であるためには、証明可能で、受け入れられ、一貫したヒューリスティック関数が必要です。 しかし、サブシーケンスの値を決定するのは簡単ではないため、そのような関数を思いつくことができる人はいないでしょう。 」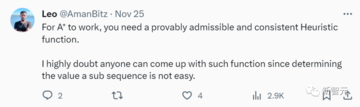 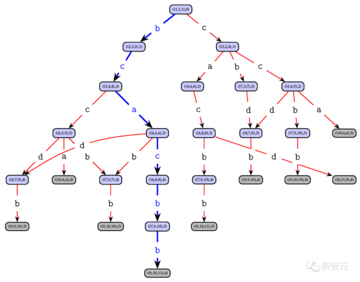 ## **小学校の算数問題を解いても、Q\*は高いことが予想されます**大規模モデルについて少しでも知っている人なら誰でも、基本的な数学的問題を解く能力は、モデルがそうする能力が大きな飛躍であることを意味することを知っています。これは、大規模なモデルがトレーニング済みデータの外部で一般化することが難しいためです。AIトレーニングのスタートアップ企業Tromeroの共同創業者であるチャールズ・ヒギンズ氏は、現在大規模モデルを悩ませている重要な問題は、抽象的な概念を論理的に推論する方法であり、このステップが達成されれば、間違いなく大きな飛躍になるだろうと述べています。数学は、たとえば、XがYより大きく、YがZより大きい場合、XはZよりも大きいという記号的推論の研究です。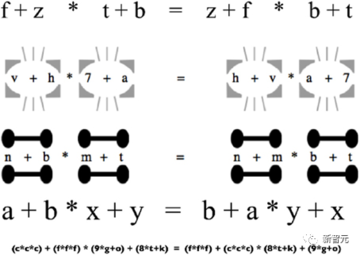 Q\*が本当にQ-learning+A\*であれば、OpenAIの新しいモデルがChatGPT対応のディープラーニング技術と人間のプログラミングのルールを組み合わせることができることを示しています。 そして、この方法は、LLMの幻覚的なパズルを解くのに役立ちます。Tromero の共同制作者である Sophia Kalanovska 氏によると、これは非常に重要な象徴的な意味を持っていますが、実際的なレベルでは、世界を終わらせる可能性は低いとのことです。では、なぜ「汎用人工知能のプロトタイプにQ\*がすでに登場している」という噂があるのでしょうか?カラノフスカは、現在の主張によれば、Q\*は脳の両側を組み合わせ、事実を推論しながら経験から物事を理解することができると主張しています。 Q\*は、ChatGPTではできない大規模なモデルに新しいアイデアを与える可能性が高いため、明らかに、これは私たちが認識しているインテリジェンスに一歩近づいています。既存のモデルの最大の限界は、トレーニングデータから情報を逆流させることしかできず、推論や新しいアイデアの開発ができないことです。目に見えない問題を解決することは、汎用人工知能を作成する上で重要なステップです。 サリー・センター・フォー・ヒューマニティ(Surrey Centre for Humanity)のAI研究所のアンドリュー・ロゴイスキー(Andrew Rogoyski)所長は、現在存在する大規模なモデルでは学部レベルの数学の問題は解けるが、より高度な数学の問題となると、すべて失敗すると述べている。しかし、LLMが本当に新しい、目に見えない問題を解くことができるなら、たとえ数学の問題が比較的単純であっても、それは大きな問題です。## **合成データはLLMの未来の鍵ですか?では、合成データは王様なのでしょうか?Q\*の爆発的な増加は、大物たちの間で多くの憶測を呼んでおり、大物たちは、噂されている「新しいモデルが特定の数学的問題を解くことを可能にする巨大なコンピューティングリソース」はRLAIF(AIフィードバックからの強化学習)ではないかと推測しています。RLAIFは、既製のLLMから人間のタグ付け設定を置き換えるテクノロジーであり、人間のフィードバックを自動化することで、LLMに対するアライメント操作をよりスケーラブルにします。 以前からLLMのトレーニングで注目されていたRLHF(Reinforcement Learning Based on Human Feedback)は、大規模言語モデルを人間の嗜好に効果的に合わせることができますが、高品質の人間の嗜好ラベルの収集が重要なボトルネックとなっています。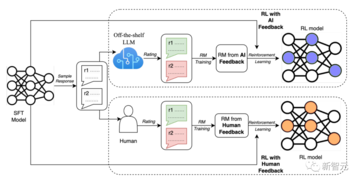 その結果、AnthropicやGoogleなどの企業はRLAIFに目を向けようとし、フィードバックトレーニングの過程でAIを使用して人間に取って代わろうとしました。つまり、合成データは王様であり、ツリー構造を使用することで、後で正しい答えに到達するための選択肢がますます増えます。少し前、Jim Fan氏は、合成データが次の1兆個の高品質なトレーニングデータを提供するとツイートしました。 「真面目なLLMグループのほとんどは、そのことを知っているに違いない。 重要な問題は、品質を維持し、時期尚早の停滞を回避する方法です。 」また、Jim Fan氏は、Richard S. Sutton氏の論文「The Bitter Lesson」を引用して、AIの開発には、計算によって無限に拡張できるパラダイムが2つしかないことを説明しています。「この記事を書いている2019年当時もそうでしたし、今日もそうです。汎用人工知能を解く日までは、きっとそうでしょう。 」リチャード・S・サットンは、カナダ王立協会および王立協会のフェローであり、現代の計算強化学習の創始者の一人と見なされており、時差学習や戦略的勾配法など、この分野にいくつかの重要な貢献をしています。 この記事で、サットンは次の点を指摘しています。コンピューティングを活用する一般的なアプローチは、最終的には最も効率的で効率的です。 しかし、その理由はムーアの法則であり、より正確には、コンピューティングの単位あたりのコストが指数関数的に継続的に低下しているためです。当初、研究者は人間の知識やゲームの特殊性を利用して検索を回避しようとしていましたが、検索が大規模に効果的に適用されると、それらはすべて無関係に思えるようになります。ここでも、統計的手法が人間の知識ベースの手法に打ち勝ち、統計と計算が何十年にもわたって徐々に支配的になった自然言語処理の分野全体に大きな変化をもたらしました。AI研究者は、知識をシステムに組み込もうとすることが多く、短期的には役に立ちますが、長期的にはさらなる進歩を妨げる可能性があります。ブレークスルーは、検索と学習ベースのアプローチによって最終的に達成されます。心の実際の内容は非常に複雑であり、思考を表現する単純な方法を見つけようとするのをやめ、代わりに、この任意の複雑さを見つけて捕らえることができるメタメソッドを構築する必要があります。- つまり、Q\*は問題の核心(探索と学習)を掴んだようで、合成データによって、過去の限界を突破し、独自の飛躍を遂げることができるようになるでしょう。合成データに関して、マスク氏は、人間は本当に機械に勝てないとも言っています。 「人間が書いたすべての本のテキストをハードドライブに保存すれば(ため息)、合成データはそれ以上のものになります。 」この点に関して、Jim Fan氏はMusk氏と対話し、次のように述べています。 「大規模にシミュレーションできれば、テスラ・オプティマスのような具体化されたエージェントから多くの合成データが得られるでしょう。 」Jim Fan氏は、RLAIF(グラウンドトゥルースフィードバックからのRLAIF)は、正しくスケーリングされれば大いに役立つと考えている。 さらに、合成データにはシミュレータが含まれており、原理的にはLLMが世界モデルを開発するのに役立ちます。 「理想的には、それは無限です。 しかし、懸念されるのは、自己改善のサイクルが十分に効果的でなければ、失速するリスクがあることです。 」2人の歌とハーモニーについて、ルカンは言いたいことがあると語った。 LeCunは、動物と人間は、ほとんどトレーニングデータがないとすぐに非常に賢くなると考えています。したがって、より多くのデータ(合成または非合成)を使用することは、現在のアプローチに限界があるため、一時的な応急処置にすぎません。この点について、「ビッグデータ派」を支持するネチズンは不満を表明した。 「何百万年にもわたる進化的適応は事前訓練に似ており、私たちの生涯の経験は継続的な微調整に似ているのではないでしょうか?」ルカンは、何百万年にもわたる進化の成果を人間が引き継ぐために用いる唯一の手段は遺伝子であり、ヒトゲノムのデータ量は非常に少なく、わずか800MBに過ぎないことを例を挙げて説明しました。 小さな7B LLMでも14GBのストレージが必要ですが、これはヒトゲノムのデータ量ではありません。また、チンパンジーとヒトのゲノムの差は約1%(8MB)です。 このわずかな違いは、人間とチンパンジーの能力の違いを説明するのに十分ではありません。学習するデータ量に関して言えば、2歳の子供が目にする視覚データは非常に少なく、学習時間全体の約3,200万秒(2x365x12x3600)です。人間には200万本の光神経線維があり、各神経線維は毎秒約10バイトを伝達します。 - 合計で 6E14 バイトです。対照的に、LLMトレーニングのデータ量は通常1E13トークンで、約2E13バイトです。 したがって、2 歳の子供は LLM の 30 倍のデータしか取得できません。大手の主張とは関係なく、Google、Anthropic、Cohereなどの大手テクノロジー企業は、プロセス監視やRLAIFのような方法を使用して事前トレーニング済みのデータセットを作成しており、膨大なリソースを消費しています。そのため、合成データがデータセットを拡張するための近道であることは誰の目にも明らかです。 短期的には、明らかにそれを使用して有用なデータを作成できます。しかし、これは未来への道なのでしょうか? 答えを待つ必要があります。リソース:
Tian Yuandong氏は、OpenAIの謎めいたQ*プロジェクトに冷や水を浴びせた:合成データは汎用人工知能の救世主ではなく、その能力は単純な数学の問題に限定されている
ソース: New Zhiyuan
Q* 予想は、AI コミュニティで引き続き人気があります。
Q* が "Q-learning + A*" であるかどうか、誰もが推測しています。
AIの第一人者である渕人田氏も、「Q*=Q-learning+A*」という仮説の蓋然性を詳細に分析しています。
同時に、合成データがLLMの未来であると判断する人が増えています。
しかし、田元東はこの発言に冷や水を浴びせた。
Q*=Q-learning+A、その可能性はどれくらいですか
Tian Yuandong氏は、OpenGo(AlphaZeroの複製)での過去の経験に基づいて、A*は値(つまりヒューリスティック)関数Qのみを持つ決定論的MCTSバージョンと見なすことができると述べました。
対照的に、囲碁は別の話で、次の候補は比較的簡単に予測できますが(局所的な形状を確認するだけで)、盤上の状況を評価するのははるかに困難です。
そのため、非常に強力な囲碁ボットもありますが、戦略ネットワークしか利用していません。
数学の問題を解くことですでに大きな飛躍を遂げている伝説のQ*、これはどれくらいの可能性がありますか?
Tian Yuandong氏は、初級レベルの数学の問題が解かれるため、値関数は比較的簡単に設定できるはずだ(たとえば、自然言語の形でターゲット仕様から予測できる)と推測していると述べた。
難しい数学の問題を解きたいが、その方法がわからない場合は、このアプローチでは不十分な場合があります。
一部のネチズンは懐疑的な見方を示し、「A*が有効であるためには、証明可能で、受け入れられ、一貫したヒューリスティック関数が必要です。 しかし、サブシーケンスの値を決定するのは簡単ではないため、そのような関数を思いつくことができる人はいないでしょう。 」
小学校の算数問題を解いても、Q*は高いことが予想されます
大規模モデルについて少しでも知っている人なら誰でも、基本的な数学的問題を解く能力は、モデルがそうする能力が大きな飛躍であることを意味することを知っています。
これは、大規模なモデルがトレーニング済みデータの外部で一般化することが難しいためです。
AIトレーニングのスタートアップ企業Tromeroの共同創業者であるチャールズ・ヒギンズ氏は、現在大規模モデルを悩ませている重要な問題は、抽象的な概念を論理的に推論する方法であり、このステップが達成されれば、間違いなく大きな飛躍になるだろうと述べています。
数学は、たとえば、XがYより大きく、YがZより大きい場合、XはZよりも大きいという記号的推論の研究です。
Tromero の共同制作者である Sophia Kalanovska 氏によると、これは非常に重要な象徴的な意味を持っていますが、実際的なレベルでは、世界を終わらせる可能性は低いとのことです。
では、なぜ「汎用人工知能のプロトタイプにQ*がすでに登場している」という噂があるのでしょうか?
カラノフスカは、現在の主張によれば、Q*は脳の両側を組み合わせ、事実を推論しながら経験から物事を理解することができると主張しています。
既存のモデルの最大の限界は、トレーニングデータから情報を逆流させることしかできず、推論や新しいアイデアの開発ができないことです。
目に見えない問題を解決することは、汎用人工知能を作成する上で重要なステップです。
しかし、LLMが本当に新しい、目に見えない問題を解くことができるなら、たとえ数学の問題が比較的単純であっても、それは大きな問題です。
**合成データはLLMの未来の鍵ですか?
では、合成データは王様なのでしょうか?
Q*の爆発的な増加は、大物たちの間で多くの憶測を呼んでおり、大物たちは、噂されている「新しいモデルが特定の数学的問題を解くことを可能にする巨大なコンピューティングリソース」はRLAIF(AIフィードバックからの強化学習)ではないかと推測しています。
RLAIFは、既製のLLMから人間のタグ付け設定を置き換えるテクノロジーであり、人間のフィードバックを自動化することで、LLMに対するアライメント操作をよりスケーラブルにします。
つまり、合成データは王様であり、ツリー構造を使用することで、後で正しい答えに到達するための選択肢がますます増えます。
少し前、Jim Fan氏は、合成データが次の1兆個の高品質なトレーニングデータを提供するとツイートしました。
また、Jim Fan氏は、Richard S. Sutton氏の論文「The Bitter Lesson」を引用して、AIの開発には、計算によって無限に拡張できるパラダイムが2つしかないことを説明しています。
「この記事を書いている2019年当時もそうでしたし、今日もそうです。汎用人工知能を解く日までは、きっとそうでしょう。 」
リチャード・S・サットンは、カナダ王立協会および王立協会のフェローであり、現代の計算強化学習の創始者の一人と見なされており、時差学習や戦略的勾配法など、この分野にいくつかの重要な貢献をしています。
コンピューティングを活用する一般的なアプローチは、最終的には最も効率的で効率的です。 しかし、その理由はムーアの法則であり、より正確には、コンピューティングの単位あたりのコストが指数関数的に継続的に低下しているためです。
当初、研究者は人間の知識やゲームの特殊性を利用して検索を回避しようとしていましたが、検索が大規模に効果的に適用されると、それらはすべて無関係に思えるようになります。
ここでも、統計的手法が人間の知識ベースの手法に打ち勝ち、統計と計算が何十年にもわたって徐々に支配的になった自然言語処理の分野全体に大きな変化をもたらしました。
AI研究者は、知識をシステムに組み込もうとすることが多く、短期的には役に立ちますが、長期的にはさらなる進歩を妨げる可能性があります。
ブレークスルーは、検索と学習ベースのアプローチによって最終的に達成されます。
心の実際の内容は非常に複雑であり、思考を表現する単純な方法を見つけようとするのをやめ、代わりに、この任意の複雑さを見つけて捕らえることができるメタメソッドを構築する必要があります。
合成データに関して、マスク氏は、人間は本当に機械に勝てないとも言っています。
この点に関して、Jim Fan氏はMusk氏と対話し、次のように述べています。
Jim Fan氏は、RLAIF(グラウンドトゥルースフィードバックからのRLAIF)は、正しくスケーリングされれば大いに役立つと考えている。 さらに、合成データにはシミュレータが含まれており、原理的にはLLMが世界モデルを開発するのに役立ちます。
2人の歌とハーモニーについて、ルカンは言いたいことがあると語った。
したがって、より多くのデータ(合成または非合成)を使用することは、現在のアプローチに限界があるため、一時的な応急処置にすぎません。
この点について、「ビッグデータ派」を支持するネチズンは不満を表明した。
ルカンは、何百万年にもわたる進化の成果を人間が引き継ぐために用いる唯一の手段は遺伝子であり、ヒトゲノムのデータ量は非常に少なく、わずか800MBに過ぎないことを例を挙げて説明しました。
また、チンパンジーとヒトのゲノムの差は約1%(8MB)です。 このわずかな違いは、人間とチンパンジーの能力の違いを説明するのに十分ではありません。
学習するデータ量に関して言えば、2歳の子供が目にする視覚データは非常に少なく、学習時間全体の約3,200万秒(2x365x12x3600)です。
人間には200万本の光神経線維があり、各神経線維は毎秒約10バイトを伝達します。 - 合計で 6E14 バイトです。
対照的に、LLMトレーニングのデータ量は通常1E13トークンで、約2E13バイトです。 したがって、2 歳の子供は LLM の 30 倍のデータしか取得できません。
大手の主張とは関係なく、Google、Anthropic、Cohereなどの大手テクノロジー企業は、プロセス監視やRLAIFのような方法を使用して事前トレーニング済みのデータセットを作成しており、膨大なリソースを消費しています。
そのため、合成データがデータセットを拡張するための近道であることは誰の目にも明らかです。 短期的には、明らかにそれを使用して有用なデータを作成できます。
しかし、これは未来への道なのでしょうか? 答えを待つ必要があります。
リソース: