- Topic1/3
29k Popularity
11k Popularity
15k Popularity
6k Popularity
14k Popularity
- Pin
- 🎉 Gate Square Growth Points Summer Lucky Draw Round 1️⃣ 2️⃣ Is Live!
🎁 Prize pool over $10,000! Win Huawei Mate Tri-fold Phone, F1 Red Bull Racing Car Model, exclusive Gate merch, popular tokens & more!
Try your luck now 👉 https://www.gate.com/activities/pointprize?now_period=12
How to earn Growth Points fast?
1️⃣ Go to [Square], tap the icon next to your avatar to enter [Community Center]
2️⃣ Complete daily tasks like posting, commenting, liking, and chatting to earn points
100% chance to win — prizes guaranteed! Come and draw now!
Event ends: August 9, 16:00 UTC
More details: https://www
- #Gate 2025 Semi-Year Community Gala# voting is in progress! 🔥
Gate Square TOP 40 Creator Leaderboard is out
🙌 Vote to support your favorite creators: www.gate.com/activities/community-vote
Earn Votes by completing daily [Square] tasks. 30 delivered Votes = 1 lucky draw chance!
🎁 Win prizes like iPhone 16 Pro Max, Golden Bull Sculpture, Futures Voucher, and hot tokens.
The more you support, the higher your chances!
Vote to support creators now and win big!
https://www.gate.com/announcements/article/45974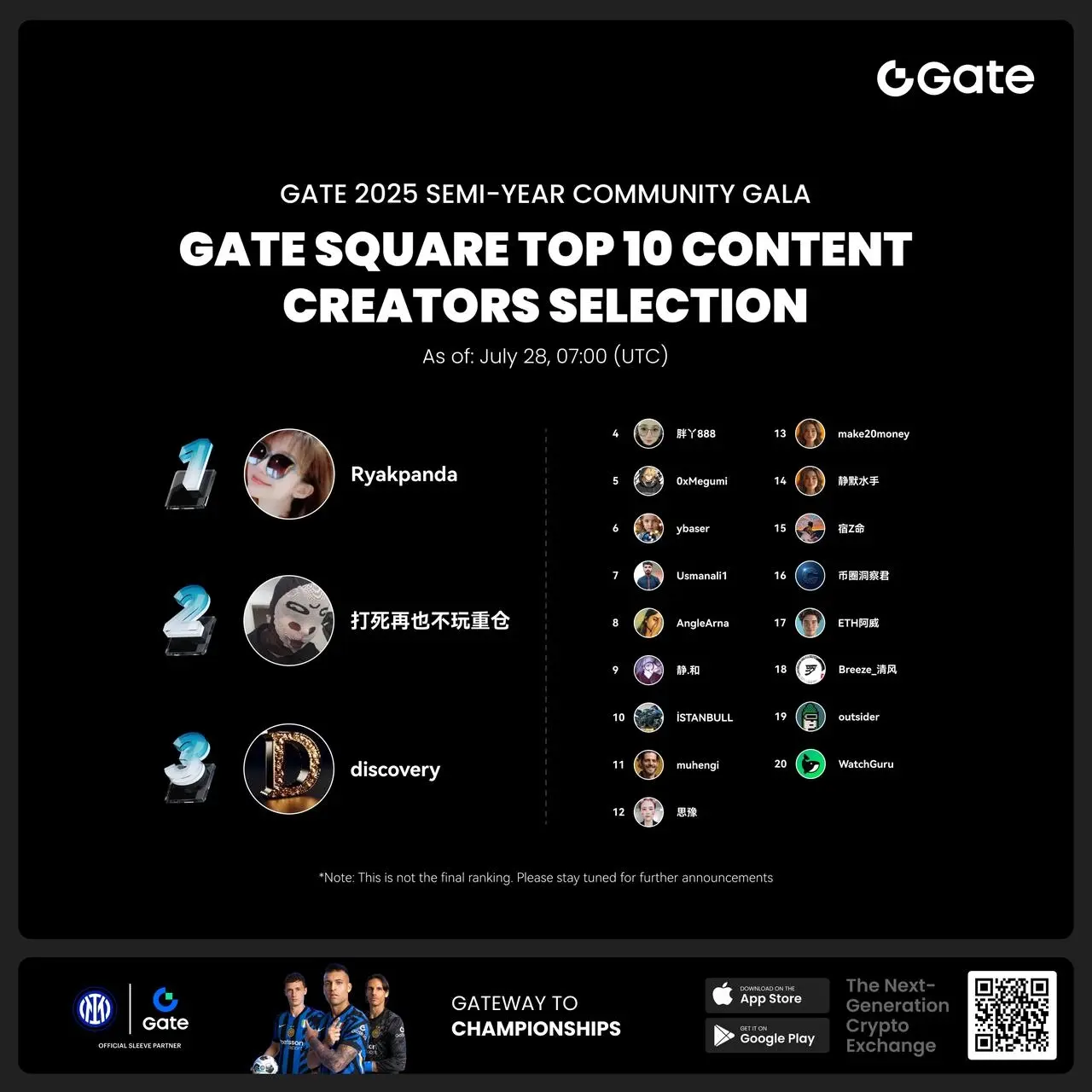
"Great shock" of a CTO: GPT-4V autonomous driving five consecutive tests
Original source: Qubits
Under the high expectation, GPT4 finally pushed vision-related functions.
This afternoon, I quickly tested GPT's ability to perceive images with my friends, and although I expected it, I still shocked us greatly.
Core Ideas:
It should be more than enough to solve some so-called efficiency-related corner cases, but it is still very far from relying on large models to complete driving independently to ensure safety.
Example1: Some unknown obstacles on the road
** Description of **###### △GPT4
Description of **###### △GPT4
Accurate part: 3 trucks detected, the number of the license plate of the front car is basically correct (ignore it if there are Chinese characters), the weather and environment are correct, Accurate identification of unknown obstacles ahead without prompting.
Inaccurate part: the position of the third truck is not divided left and right, and the text on the top of the head of the second truck guesses one blindly (because of insufficient resolution?). )。
That's not enough, let's continue to give a little hint and ask what this object is and whether it can be pressed over.
Example2: Understanding of Water in Pave
Example3: A vehicle turned around and hit the guardrail
Example4: Let's have a funny
Example5 Come to a famous scene... Delivery vehicles strayed into new roads
After using CoT, the problem found is that it is not understood that the car is an autonomous vehicle, so by giving this information, it can give more accurate information.
Finally, through a bunch, it is possible to output the conclusion that newly laid asphalt is not suitable for driving. The end result is still OK, but the process is more tortuous, and more engineering is required, and it is necessary to design well.
This reason may also be because it is not a first-view picture, and can only be speculated through the third-point view. So this example is not very precise.
Summary
Some quick attempts have fully proved the power and generalization performance of GPT4V, and the appropriate should be able to fully exert the strength of GPT4V.
Solving the semantic corner case should be very desirable, but the problem of hallucinations will still plague some applications in safety-related scenarios.
Very exciting, I personally think that the reasonable use of such a large model can greatly accelerate the development of L4 and even L5 autonomous driving, but does LLM necessarily drive directly? End-to-end driving, in particular, remains a debatable issue.
Reference Links: