zkPyTorch: Bringing Zero-Knowledge Proofs to PyTorch Inference for Truly Trustworthy AI
As artificial intelligence (AI) is increasingly being implemented in key areas such as healthcare, finance, and autonomous driving, ensuring the reliability, transparency, and security of the machine learning (ML) inference process is becoming more important than ever.
However, traditional machine learning services often operate like a “black box,” where users can only see the results and find it difficult to verify the process. This lack of transparency makes model services vulnerable to risks:
The model has been stolen,
The inference result has been maliciously tampered with,
User data is at risk of privacy breaches.
ZKML (zk-SNARKs Machine Learning) provides a new cryptographic solution to this challenge. It relies on zk-SNARKs technology, granting machine learning models the ability to be verifiably encrypted: proving that a computation has been executed correctly without revealing any sensitive information.
In other words, ZKPs allow service providers to prove to users that:
“The inference results you obtained are indeed generated by the trained model I ran — but I will not disclose any model parameters.”
This means that users can trust the authenticity of the inference results, while the structure and parameters of the model (which are often high-value assets) remain private.
zkPyTorch:
Polyhedra Network has launched zkPyTorch, a revolutionary compiler specially designed for zero-knowledge machine learning (ZKML), aimed at bridging the last mile between mainstream AI frameworks and ZK technology.
zkPyTorch deeply integrates the powerful machine learning capabilities of PyTorch with cutting-edge zk-SNARKs engines, allowing AI developers to build verifiable AI applications in a familiar environment without changing their programming habits or learning a completely new ZK language.
This compiler can automatically translate high-level model operations (such as convolution, matrix multiplication, ReLU, softmax, and attention mechanisms) into cryptographically verifiable ZKP circuits. It combines Polyhedra’s self-developed ZKML optimization suite to intelligently compress and accelerate mainstream inference paths, ensuring both correctness and computational efficiency of the circuits.
Key infrastructure for building a trustworthy AI ecosystem
The current machine learning ecosystem is facing multiple challenges such as data security, computational verifiability, and model transparency. Especially in critical industries like healthcare, finance, and autonomous driving, AI models not only involve a large amount of sensitive personal information but also carry high-value intellectual property and core business secrets.
Zero-Knowledge Machine Learning (ZKML) has emerged as an important breakthrough in addressing this dilemma. Through Zero-Knowledge Proof (ZKP) technology, ZKML can complete the integrity verification of model inference without disclosing model parameters or input data—protecting privacy while ensuring trust.
But in reality, developing ZKML often has a high threshold, requiring a deep background in cryptography, which is far from what traditional AI engineers can easily handle.
This is precisely the mission of zkPyTorch. It builds a bridge between PyTorch and the ZKP engine, allowing developers to construct AI systems with privacy protection and verifiability using familiar code, without the need to relearn complex cryptographic languages.
Through zkPyTorch, Polyhedra Network is significantly lowering the technical barriers of ZKML, driving scalable and trusted AI applications into the mainstream, and reconstructing a new paradigm of AI security and privacy.
zkPyTorch workflow

Figure 1: Overview of the overall architecture of ZKPyTorch
As shown in Figure 1, zkPyTorch automatically converts standard PyTorch models into circuits compatible with ZKP (zk-SNARKs) through three carefully designed modules. These three modules include: preprocessing module, zero-knowledge friendly quantization module, and circuit optimization module.
This process does not require developers to master any cryptographic circuits or specialized syntax: developers only need to write models using standard PyTorch, and zkPyTorch can convert them into circuits that can be recognized by zero-knowledge proof engines such as Expander, generating the corresponding ZK proof.
This highly modular design significantly lowers the development threshold of ZKML, allowing AI developers to easily build efficient, secure, and verifiable machine learning applications without the need to switch languages or learn cryptography.
Block One: Model Preprocessing
In the first phase, zkPyTorch will convert the PyTorch model into a structured computation graph using the Open Neural Network Exchange format (ONNX). ONNX is an industry-wide adopted intermediate representation standard that can uniformly represent various complex machine learning operations. Through this preprocessing step, zkPyTorch is able to clarify the model structure and break down the core computation process, laying a solid foundation for generating zk-SNARKs circuits in the subsequent steps.
Module 2: ZKP Friendly Quantification
The quantization module is a key component of the ZKML system. Traditional machine learning models rely on floating-point operations, while the ZKP environment is more suitable for integer operations in finite fields. zkPyTorch adopts an integer quantization scheme optimized for finite fields, accurately mapping floating-point computations to integer computations, while transforming nonlinear operations that are unfavorable for ZKP (such as ReLU and Softmax) into efficient lookup table forms.
This strategy not only significantly reduces circuit complexity but also enhances the overall system’s verifiability and operational efficiency while ensuring model accuracy.
Module 3: Hierarchical Circuit Optimization
zkPyTorch adopts a multi-level strategy for circuit optimization, specifically including:
Batch optimization
Specifically designed for serialized computation, it significantly reduces computational complexity and resource consumption by processing multiple inference steps at once, making it especially suitable for verification scenarios of large language models such as Transformers.
Original Language Operation Acceleration
By combining Fast Fourier Transform (FFT) convolution with lookup table technology, the execution speed of basic operations such as convolution and Softmax is effectively enhanced, fundamentally improving overall computational efficiency.
Parallel circuit execution
Fully leverage the computational power advantages of multi-core CPUs and GPUs by splitting heavy-load computations like matrix multiplication into multiple sub-tasks for parallel execution, significantly improving the speed and scalability of zk-SNARKs generation.
In-depth Technical Discussion
Directed Acyclic Graph (DAG)
zkPyTorch uses a Directed Acyclic Graph (DAG) to manage the computational flow of machine learning. The DAG structure systematically captures complex model dependencies, as shown in Figure 2, where each node represents a specific operation (such as matrix transposition, matrix multiplication, division, and Softmax), and the edges precisely describe the data flow between these operations.
This clear and structured representation not only greatly facilitates the debugging process but also helps in the in-depth optimization of performance. The acyclic nature of the DAG avoids circular dependencies, ensuring efficient and controllable execution of the computation order, which is crucial for optimizing zk-SNARKs circuit generation.
In addition, DAG enables zkPyTorch to efficiently handle complex model architectures such as Transformers and Residual Networks (ResNet), which often have multi-path, non-linear complex data flows. The design of DAG perfectly aligns with their computational needs, ensuring the accuracy and efficiency of model inference.

Figure 2: An example of a machine learning model represented as a directed acyclic graph (DAG)
Advanced Quantitative Techniques
In zkPyTorch, advanced quantization techniques are a key step in converting floating-point computations into integer operations suitable for efficient finite field arithmetic in zero-knowledge proof (ZKP) systems. zkPyTorch employs a static integer quantization method, carefully designed to balance computational efficiency and model accuracy, ensuring that proof generation is both fast and accurate.
This quantization process involves strict calibration to accurately determine the optimal quantization scale for effectively representing floating-point numbers, avoiding overflow and significant loss of precision. To address the unique nonlinear operation challenges of ZKP (such as Softmax and layer normalization), zkPyTorch innovatively transforms these complex functions into efficient table lookup operations.
This strategy not only significantly improves the efficiency of proof generation but also ensures that the generated proof results are completely consistent with the outputs of high-precision quantitative models, balancing performance and credibility, and advancing the practical application of verifiable machine learning.
Multi-level circuit optimization strategy
zkPyTorch adopts a highly sophisticated multi-layer circuit optimization system, ensuring the ultimate performance of zero-knowledge reasoning in terms of efficiency and scalability from multiple dimensions:
Batch Processing Optimization
By packaging multiple inference tasks into batch processing, the overall computational complexity is significantly reduced, especially suitable for sequential operations in language models like Transformers. As shown in Figure 3, the traditional inference process of large language models (LLM) runs in a token-by-token generation manner, while zkPyTorch’s innovative approach aggregates all input and output tokens into a single prompt process for validation. This processing method can confirm the overall correctness of the LLM’s inference at once, while ensuring that each output token is consistent with standard LLM inference.
In LLM inference, the correctness of the KV cache (key-value cache) mechanism is key to ensuring the reliability of inference outputs. If the model’s inference logic is incorrect, even with caching, it cannot reproduce results consistent with the standard decoding process. zkPyTorch ensures that every output in zk-SNARKs has verifiable determinism and completeness by precisely replicating this process.
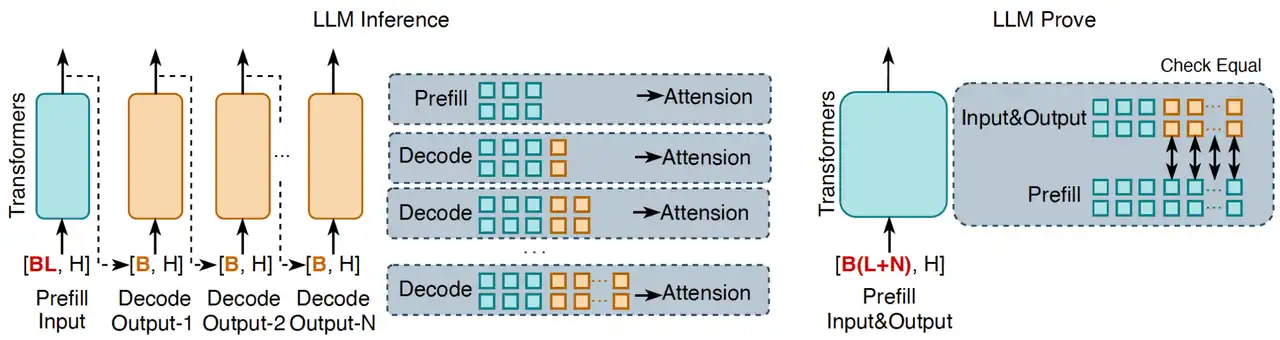
Figure 3: Batch verification of large-scale language models (LLMs), where L represents the input sequence length, N represents the output sequence length, and H represents the model’s hidden layer dimension.
Optimized Primitive Operations
zkPyTorch has deeply optimized the underlying machine learning primitives, greatly enhancing circuit efficiency. For example, convolution operations have always been compute-intensive tasks; zkPyTorch uses an optimization method based on Fast Fourier Transform (FFT) to convert convolutions originally executed in the spatial domain into multiplication operations in the frequency domain, significantly reducing computational costs. At the same time, for non-linear functions such as ReLU and softmax, the system employs a pre-calculated lookup table approach, avoiding non-linear computations that are not ZKP-friendly, greatly improving the operational efficiency of inference circuits.
Parallel Circuit Execution
zkPyTorch automatically compiles complex ML operations into parallel circuits, fully utilizing the hardware potential of multi-core CPUs/GPUs to achieve large-scale parallel proof generation. For example, when performing tensor multiplication, zkPyTorch automatically splits the computation task into multiple independent sub-tasks, which are then distributed to multiple processing units for concurrent execution. This parallelization strategy not only significantly improves the throughput of circuit execution but also makes the efficient verification of large models a reality, opening up new dimensions for scalable ZKML.
Comprehensive performance testing: a dual breakthrough in performance and accuracy
zkPyTorch demonstrates exceptional performance and practical usability across multiple mainstream machine learning models through rigorous benchmarking:
VGG-16 model testing
On the CIFAR-10 dataset, zkPyTorch takes only 6.3 seconds to generate a VGG-16 proof for a single image, and the accuracy is almost indistinguishable from traditional floating-point computation. This marks the practical capabilities of zkML in classical tasks such as image recognition.
Llama-3 model testing
For the Llama-3 large language model with up to 8 billion parameters, zkPyTorch achieves efficient proof generation of around 150 seconds per token. Even more impressively, its output maintains a cosine similarity of 99.32% compared to the original model, ensuring high credibility while still preserving the semantic consistency of the model’s output.

Table 1: Performance of various ZKP schemes in convolutional neural networks and transformer networks
A wide range of application scenarios in the real world
Verifiable MLaaS
As the value of machine learning models continues to rise, more and more AI developers are choosing to deploy their self-developed models to the cloud, offering MLaaS (Machine-Learning-as-a-Service) services. However, in reality, users often find it difficult to verify whether the inference results are authentic and trustworthy; meanwhile, model providers also wish to protect core assets such as model structure and parameters to prevent theft or misuse.
zkPyTorch was born to solve this contradiction: it enables cloud AI services to have native “zero-knowledge verification capabilities,” achieving verifiable encryption-level inference results.
As shown in Figure 4, developers can directly integrate large models such as Llama-3 into zkPyTorch to build a trustworthy MLaaS system with zero-knowledge proof capabilities. By seamlessly integrating with the underlying ZKP engine, zkPyTorch can automatically generate proofs without exposing model details, verifying whether each inference is executed correctly, thereby establishing a truly trustworthy interactive trust foundation for model providers and users.

Figure 4: The application scenarios of zkPyTorch in Verifiable MLaaS.
The secure escort of model valuation
zkPyTorch provides a secure and verifiable AI model evaluation mechanism, allowing stakeholders to prudently assess key performance indicators without exposing the model’s details. This “zero leakage” valuation method establishes a new trust standard for AI models, enhancing the efficiency of commercial transactions while safeguarding the intellectual property rights of developers. It not only increases the visibility of the model’s value but also brings greater transparency and fairness to the entire AI industry.
Deep integration with the EXPchain blockchain
zkPyTorch natively integrates with the EXPchain blockchain network independently developed by Polyhedra Network, jointly building a trustworthy decentralized AI infrastructure. This integration provides a highly optimized path for smart contract calls and on-chain verification, allowing AI inference results to be cryptographically verified and permanently stored on the blockchain.
With the collaboration of zkPyTorch and EXPchain, developers can build end-to-end verifiable AI applications, from model deployment, inference computation to on-chain verification, truly realizing a transparent, trustworthy, and auditable AI computing process, providing underlying support for the next generation of blockchain + AI applications.
Future Roadmap and Continuous Innovation
Polyhedra will continue to advance the evolution of zkPyTorch, focusing on the following aspects:
Open source and community co-construction
Gradually open source the core components of zkPyTorch, inspiring global developers to participate and promoting collaborative innovation and ecological prosperity in the field of zero-knowledge machine learning.
Expand model and framework compatibility
Expand the support range for mainstream machine learning models and frameworks, further enhance the adaptability and versatility of zkPyTorch, making it flexible to integrate into various AI workflows.
Development Tools and SDK Construction
Launch a comprehensive development toolchain and software development kit (SDK) to simplify the integration process and accelerate the deployment and application of zkPyTorch in practical business scenarios.
Conclusion
zkPyTorch is an important milestone towards a trustworthy AI future. By deeply integrating the mature PyTorch framework with cutting-edge zk-SNARKs technology, zkPyTorch not only significantly enhances the security and verifiability of machine learning but also reshapes the deployment methods and trust boundaries of AI applications.
Polyhedra will continue to innovate in the field of “secure AI”, advancing machine learning towards higher standards in privacy protection, result verifiability, and model compliance, helping to build transparent, trustworthy, and scalable intelligent systems.
Stay tuned for our latest updates and witness how zkPyTorch is reshaping the future of the secure intelligent era.
Statement:
- This article is reproduced from [BLOCKBEATS] The copyright belongs to the original author [Jiaheng Zhang] If you have any objections to the reprint, please contact Gate Learn TeamThe team will process it as quickly as possible according to the relevant procedures.
- Disclaimer: The views and opinions expressed in this article are solely those of the author and do not constitute any investment advice.
- Other language versions of the article are translated by the Gate Learn team, unless otherwise mentioned.GateUnder such circumstances, copying, distributing, or plagiarizing translated articles is not allowed.
Share
Content
zkPyTorch:
Key infrastructure for building a trusted AI ecosystem
zkPyTorch Workflow
In-depth technical discussion
Advanced Quantitative Techniques
Multi-level circuit optimization strategy
Comprehensive performance testing: a dual breakthrough in performance and accuracy
Wide range of application scenarios in the real world
The secure escort of model valuation
Deep integration with the EXPchain blockchain
Future Roadmap and Continuous Innovation
Conclusion
Related articles

Arweave: Capturing Market Opportunity with AO Computer

The Upcoming AO Token: Potentially the Ultimate Solution for On-Chain AI Agents

Dimo: Decentralized Revolution of Vehicle Data

AI Agents in DeFi: Redefining Crypto as We Know It

Mind Network: Fully Homomorphic Encryption and Restaking Bring AI Project Security Within Reach
