元のソース:シリコンベースのラボ著者: バイ・ジアジア 画像ソース:無制限のAIによって生成NVIDIAは、今回はそのパフォーマンスが急上昇するためではなく、マイクロソフト、OpenAI、グーグルなどの人工知能の「異なる心」のために、再び先端に置かれました。情報によると、マイクロソフトは来月の年次開発者会議で人工知能用に設計された最初のチップを発売する予定です。 このチップは、大規模言語モデル(LLM)をトレーニングおよび実行するデータセンターサーバー向けに設計されています。 OpenAIは、独自のAIチップの作成も検討しています。 公開情報によると、OpenAIは少なくとも3つのチップ企業に投資しています。Googleの自社開発チップTPUは、v5世代に反復されます。 以前、アナリストは、GoogleのコンピューティングパワーリソースはOpenAI、Meta、Amazon、Oracle、CoreWeaveを合わせたものよりも多く、その利点は多数のTPUを持つことから来ているというニュースを報じました。**これらの企業がコアを作りたい理由は、主にNVIDIAのGPU価格が高すぎて生産能力が不十分であるため、市場で多くの分析が行われてきました。 自社開発のチップを通じて、人工知能チップの分野でのNVIDIAの価格決定力を弱めると同時に、自社開発のチップを持たない企業よりも戦略的な自律性を持つことが期待されます。 **しかし、自社開発のチップは本当にNvidiaにその手の中の鎌を遅くすることを強制することができますか?1つの事実は、市場に出回っているH100 GPUが元の価格の2倍に上昇し、需要が依然として供給を上回っていることです。 自社開発のチップを「発売」したGoogleでさえ、NVIDIAのチップを大量に購入しています。なぜでしょうか。NVIDIAのGPUの売上は非常に明るいため、単にハードウェア会社として定義されることがよくあります。 しかし、多くの人が知らないのは、NVIDIAにはハードウェアエンジニアよりもソフトウェアエンジニアが多いということです。この文の背後にある意味は、NVIDIAの本当の堀は、新しいチップの無限の出現からではなく(もちろん、これも注目に値します)、ソフトウェアとハ ードウェアのエコロジーから来ているということです。 **一方、CUDAはこの堀の最初の堤防です。 ## **NVIDIAの本当のエース - CUDA** 2019年、NVIDIAのCEOであるジェンセンファンは、ミルウォーキー工科大学での企業開発の歴史を紹介する際に次のように述べています。「分子動力学、計算物理学から天体物理学、素粒子物理学、高エネルギー物理学まで、これらのさまざまな科学分野が私たちの技術を採用し始めています。これは、今後の最良のソリューションであるためです。」 そして、私たちはこの貢献を深く誇りに思っています。 "**NVIDIAが誇りに思っているこのテクノロジーはCUDAです。 **CUDAはNVIDIAによって発売された並列コンピューティングアーキテクチャであり、GPUがCPUを打ち負かし、今日のビッグデータコンピューティングを実行するための基盤になることができるのは幸いです。 同じタスクを実行すると、CUDAシステムをサポートするNVIDIA GPUはCPUよりも10〜100倍高速になります。なぜCUDAはこの魔法を持っているのですか?CPUとGPUはどちらも計算タスクを実行できるコンピュータープロセッサですが、違いは、CPUは線形コンピューティングに優れているのに対し、GPUは並列コンピューティングに優れていることです。 業界での一般的なアナロジーは、CPUは大学教授のようなものであり、さまざまな複雑な問題を独立して解決できますが、段階的に進むと、GPUは小学生のグループのようなものであり、シングルコアの計算能力はCPUほど良くありませんが、勝利は多数のコアにあり、同時に計算することができます。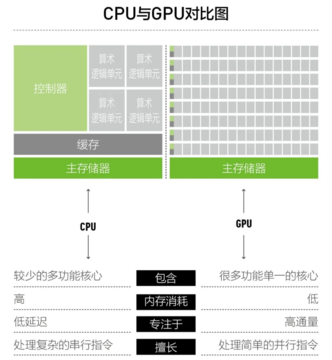 一方、CUDAは、この小学生のグループを動員するバトンです。 **CUDAの仲介により、研究者とプログラマーはプログラミング言語を介してハードウェア施設と通信し、複雑な数学的問題をGPUの複数のコンピューティングコアに分散される複数の単純な小さな問題に変換できます。 **黄が言ったように、CUDAは「科学的発展のための最良のソリューション」になり、巨大な計算能力がスーパーコンピューターを構築するための最初の選択肢になりました。10月11日、米国エネルギー省傘下のオークリッジ国立研究所は、開発したスーパーコンピューター「サミット」が、スーパーコンピューター「Sunway Taihu Light」のほぼ2倍の速度である毎秒20億回の浮動小数点演算をピークにできると発表しました。このコンピューティングパワーの巨人は、約28,000のNVIDIAGPUを搭載しています。 オークリッジ国立研究所は、NVIDIA の "CUDA+GPU" パッケージを採用した最初の機関です。実際、NVIDIAが2006年にCUDAを立ち上げて以来、コンピューターコンピューティングに関連するすべての分野は、ほぼNVIDIAの形に形作られてきました。 航空宇宙、バイオサイエンス研究、機械および流体シミュレーション、およびエネルギー探査の研究の80%は、CUDAに基づいて行われています。**さらに、大型モデルの流行に後押しされて、CUDAエコロジカルコラボレーターの規模は依然として倍増しています。 **NVIDIAの2023年度年次報告書によると、現在400万人の開発者がCUDAを使用しています。 NVIDIAは12年間で200万人の開発者に到達し、過去2年半でその数を2倍にし、CUDAは現在4,000万回以上ダウンロードされています。同時に、NVIDIAはまだCUDAエコシステムを拡大しており、ソフトウェアアクセラレーションライブラリのコレクションであるCUDA-X AIを立ち上げました。 CUDA上に構築されたこれらのライブラリは、ディープラーニング、機械学習、ハイパフォーマンスコンピューティングに不可欠な最適化機能を提供し、データサイエンスアクセラレーションのためのエンドツーエンドのプラットフォームです。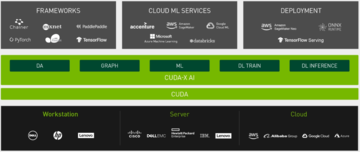 CUDAエコシステムは活況を呈しており、それを補完するGPUは消費者にとって最初の選択肢になり、NVIDIAは多くのお金を稼いでいます。 しかし、そのような大きなケーキに直面して、競合他社は当然それを見ることができません。たとえば、AMDは、多くのコンピューティングフレームワークとも互換性のあるエコロジカルプラットフォームROCmを立ち上げました。 OpenAIのTritonは、CUDAの最強の挑戦者と見なされています。 Appleによって設計され、後にKhronos Groupによって保守されたオープンソースアーキテクチャであるOpenCLは、CUDAの成功を利用し、マルチコアCPU、GPU、またはその他のアクセラレータを可能な限りサポートします。 Googleは「TPU+TensorFlow + Cloud」モデルを使用して、開発者を引き付け、顧客を拡大しています。しかし、これらの「理論的な」競合他社は、実際にはあらゆる種類の問題を明らかにしています。2月、半導体調査・コンサルティング会社Semi Analysisの主席アナリストであるDylan Patel氏は、「機械学習におけるNvidiaのCUDA独占が破綻している方法-OpenAI Triton and PyTorch 2.0」というタイトルの記事を書いた。記事のメッセージの中で、プログラマーは次のように述べています。「そう願っていますが、私は非常に懐疑的です。 私が使用するものはすべてCUDA上に構築されています。 実際、NVidia以外のハードウェアには機能がありません。 「実際に効果的」は「理論的に効果的」と同じではありません。 私が使用するものの多くは理論的にはROCmをサポートしていますが、実際には、それを使用しようとすると、大小のバグが発生し、クラッシュしたり機能したりします。 "** 第一線の研究者の発言は、ソフト・ハードともにトップの地位を保ち、20年近く市場を開拓してきたNVIDIAを前に、少なくとも現段階では、どの企業も正面から対抗できないことを証明している。 ** ## ** 「世界を再発明する」から生まれたNVIDIA帝国** NVIDIAがCUDAの切り札をつまんだのはなぜですか? 2006年にCUDAが発売されてから18年近くが経過したのに、なぜNVIDIAの堀は破られなかっただけでなく、どんどん広くなったのでしょうか。これらの質問の背後にはデフォルトの前提があります - CUDAは「正しい」方向です。 そして、NVIDIAが必死だった21世紀の初めに、このフレーズHuang Jensenは株主と市場に何千回も繰り返しました。 **素晴らしい世界を望むなら、まずはそれをシミュレートします。 ある意味で、このアイデアはGPU時代の起源であり、これらの複雑な物理法則をシミュレートし、それらを写真の形で提示します。 ただし、物理法則をシミュレートするアプリケーションは空から落ちることはなく、1つずつ開発する必要があります。したがって、GPUの計算能力が将来CPUを超える可能性が高いことが示されたとしても、アプリケーションの欠如、プログラミングプロセスは面倒であり、低レベルの言語表現の欠如は依然としてプログラマーをそれから遠ざけます。2003年、Intelは4コアCPUを導入し、競争するために、NVIDIAはユニファイドコンピューティングデバイスアーキテクチャテクノロジー(CUDA)の開発を開始しました。 このアイデアは、チーフサイエンティストのデビッドカーク博士によって提案され、後にジェンセンファンにNVIDIAの将来のすべてのGPUはCUDAをサポートする必要があると確信させました。 コンピュータ高性能コンピューティングの分野で重要な役割を果たしたため、カークは後に「CUDAの父」として知られるようになり、全米工学アカデミーに選出されました。**これらの称賛はすべてあとがきであり、黄が当時解決する必要があった問題は、回収期間が10年以上になる可能性のある未来のために戦うために製品のコストを2倍にする必要があることを株主に受け入れさせる方法でした。 **実際、CUDAをめぐる疑念はAI時代前夜まで続き、NVIDIAの時価は長年10億ドル台で推移し、CUDAの追加費用の引きずりで株価は1.50ドルまで下落しました。 株主は、収益性の改善に焦点を当てることへの期待を繰り返し上げています。2010年、当時のCPUの王様であるIntelは、Nvidiaの買収を計画していると噂されていました。 「Chip Wars」は、「インテルにとって、(Nvidiaの買収の)価格は問題ではなく、問題は黄ジェンクスンにどのようなポジションを与えるかです」と説明しています。 しかし、双方は合意に達することはなく、結局、それは解決されませんでした。 "**弱気なNVIDIAのこれらすべての年において、黄はCUDAの価値に疑問を呈したことはありません。 **開発者にアプリケーションを作成し、GPUの利点を実証するように促すために、Huangは最初に、当時ゲーマーにとってすでに大きな市場を持っていたGeForce GPUをCUDAをインストールするための基礎として使用しました。 その後、世界中でCUDAを精力的に宣伝するために、GTCと呼ばれる会議が作成されました。近年最も賞賛されているケースの1つは、2016年にHuang Jenxunが当時確立されたOpenAIに個人的にアクセスして通信を行い、当時NVIDIAの最も強力な浮動小数点コンピューティングGPUであった8つのP100チップを搭載したDGX-1を発表したことです。 この事件はしばしば黄の古いビジョンとして解釈されますが、彼にとって、それはCUDAが最先端の科学研究者にとって最も慣れ親しんだフレームワークであることを保証するための単なる別の試みです。NVIDIAの決意とは対照的に、それはインテルです。CPU時代の王として、インテルはNVIDIAの最も競争力のあるライバルになるはずでした。しかし、2010年にCPUとGPUのコンバージェンスのためのディスクリートグラフィックス計画をキャンセルした後、IntelはNVIDIAと直接対決することに興味を失いました(もちろん、ナノプロセスが行き詰まったため、自信を失ったと言えます)。 **最初にNVIDIAの買収を試み、その後、モバイルベースバンド市場でクアルコムと向きを変えて競争し、2015年に人工知能ブームの最初の波が押し寄せたとき、大きな夢で目覚めたIntelは、片手で人工知能の方向にチップ会社を買収し、AMDのチップを独自のシステムチップに組み込みました。残念ながら、当時、NVIDIAの市場シェアは60%を超え、CUDAの独占が具体化し始めており、GPU分野では、IntelはNVIDIAと同じテーブルに座る資格がなくなりました。 ## **DPU と DOCA、NVIDIA の新しい戦場** 2020年、ベンチャーキャピタル界で人気のジョークがありました。「DPUとは何ですか?」「アリペイが到着しました、1億元。」キーワードDPUがトリガーされるとすぐに、お金がロールインします。DPU熱のこのラウンドは、まさにNVIDIAが始めたものです。2020年上半期、NVIDIAはイスラエルのネットワークチップ会社メラノックステクノロジーズを69億ドルで買収し、同年にBlueField-2 DPUを発売し、CPUとGPUに次ぐ「第3のメインチップ」と定義しました。 ## **では、DPUとは正確には何ですか? ** **DPUのコア機能は、CPUを置き換え、データ中心のコンピューティングアーキテクチャを確立することです。 **ご存知のように、CPUのフルネームは中央処理装置であり、アプリケーションの実行と計算の実行に加えて、GPU、ストレージ、FPGA、その他のデバイス間でデータを移動するデータフローコントローラーの役割も果たします。校長先生が難しい問題を投げた後、先生(CPU)が分割し、より複雑な部分は自分で解決し、生徒(GPU)に配布するのは簡単ですが面倒です。 以前は、質問の数は比較的少なく、教師はまだそれを分割することができました。 ただし、質問の数が増えると、質問を分割して配布する時間が教師の時間の多くを占めます。現時点では、トピックの分割と配布を専門とする人を雇うことが、システムの全体的なコンピューティング効率を向上させるための鍵となっています。 そしてDPUはその人です。**近年、データセンター構築の急速な拡大、ネットワーク帯域とデータ量、CPUパフォーマンスの成長の鈍化により、将来のコンピューティングチップのニーズに適応することがますます困難になり、DPUが登場しています。 **これはNVIDIAのウェブサイトで定義されている方法です-DPUはデータセンターインフラストラクチャのための高度なコンピューティングプラットフォームです。 GPUがCUDAエコシステムでサポートされているように、Huang JenxunもDPUのソフトウェアエコロジーを調整し、同時にDOCAを立ち上げました。DOCA を使用すると、開発者は、ソフトウェア定義のクラウドネイティブな DPU アクセラレーション サービスを作成することで将来のデータセンター インフラストラクチャをプログラムし、ゼロトラスト保護をサポートして、最新のデータセンターの増大するパフォーマンスとセキュリティの要求を満たすことができます。CUDAとは異なり、すでに成功しているNVIDIAは、ベンチャーキャピタルサークルのDPU熱がこれを説明するのに十分であるため、市場に独自のビジョンを丹念に証明する必要がなくなりました。ただし、それに伴い、DPU市場での競争はGPUよりもはるかに熾烈です。 **外国メーカーでは、マーベル、インテル、AMDがDPUまたはDPUアライメント製品を開発しています。 中国では、Yunbao Intelligence、Zhongke Yushu、Xinqiyuan、Yunmai Xinlian、Nebulas Zhilian、Dayu Zhixinなど、多くのDPUスタートアップも出現しています。クラウドベンダーに関しては、AmazonのAWSとAlibaba Cloudが大規模な商用DPUアーキテクチャを実現し、TencentとByteDanceがDPUの研究開発軍に加わり、そのうちTencentはMetasequoiaとYinshanの2世代のDPUを立ち上げました。今回、NVIDIA は DPU+DOCA のソフトウェアとハードウェアのエコロジーを利用して、GPU + CUDA の奇跡を再現できるでしょうか。**国と企業間の計算能力をめぐる競争は激化しており、生産能力が限られており、DOCAエコシステムがまだ形成されていない場合、対戦相手には機会がないわけではありません。 **
NVIDIAの「鎌」はAIチップではありません
元のソース:シリコンベースのラボ
著者: バイ・ジアジア
NVIDIAは、今回はそのパフォーマンスが急上昇するためではなく、マイクロソフト、OpenAI、グーグルなどの人工知能の「異なる心」のために、再び先端に置かれました。
情報によると、マイクロソフトは来月の年次開発者会議で人工知能用に設計された最初のチップを発売する予定です。 このチップは、大規模言語モデル(LLM)をトレーニングおよび実行するデータセンターサーバー向けに設計されています。 OpenAIは、独自のAIチップの作成も検討しています。 公開情報によると、OpenAIは少なくとも3つのチップ企業に投資しています。
Googleの自社開発チップTPUは、v5世代に反復されます。 以前、アナリストは、GoogleのコンピューティングパワーリソースはOpenAI、Meta、Amazon、Oracle、CoreWeaveを合わせたものよりも多く、その利点は多数のTPUを持つことから来ているというニュースを報じました。
**これらの企業がコアを作りたい理由は、主にNVIDIAのGPU価格が高すぎて生産能力が不十分であるため、市場で多くの分析が行われてきました。 自社開発のチップを通じて、人工知能チップの分野でのNVIDIAの価格決定力を弱めると同時に、自社開発のチップを持たない企業よりも戦略的な自律性を持つことが期待されます。 **
しかし、自社開発のチップは本当にNvidiaにその手の中の鎌を遅くすることを強制することができますか?
1つの事実は、市場に出回っているH100 GPUが元の価格の2倍に上昇し、需要が依然として供給を上回っていることです。 自社開発のチップを「発売」したGoogleでさえ、NVIDIAのチップを大量に購入しています。
なぜでしょうか。
NVIDIAのGPUの売上は非常に明るいため、単にハードウェア会社として定義されることがよくあります。 しかし、多くの人が知らないのは、NVIDIAにはハードウェアエンジニアよりもソフトウェアエンジニアが多いということです。
この文の背後にある意味は、NVIDIAの本当の堀は、新しいチップの無限の出現からではなく(もちろん、これも注目に値します)、ソフトウェアとハ ードウェアのエコロジーから来ているということです。 **
一方、CUDAはこの堀の最初の堤防です。
NVIDIAの本当のエース - CUDA
2019年、NVIDIAのCEOであるジェンセンファンは、ミルウォーキー工科大学での企業開発の歴史を紹介する際に次のように述べています。
「分子動力学、計算物理学から天体物理学、素粒子物理学、高エネルギー物理学まで、これらのさまざまな科学分野が私たちの技術を採用し始めています。これは、今後の最良のソリューションであるためです。」 そして、私たちはこの貢献を深く誇りに思っています。 "
**NVIDIAが誇りに思っているこのテクノロジーはCUDAです。 **
CUDAはNVIDIAによって発売された並列コンピューティングアーキテクチャであり、GPUがCPUを打ち負かし、今日のビッグデータコンピューティングを実行するための基盤になることができるのは幸いです。 同じタスクを実行すると、CUDAシステムをサポートするNVIDIA GPUはCPUよりも10〜100倍高速になります。
なぜCUDAはこの魔法を持っているのですか?
CPUとGPUはどちらも計算タスクを実行できるコンピュータープロセッサですが、違いは、CPUは線形コンピューティングに優れているのに対し、GPUは並列コンピューティングに優れていることです。 業界での一般的なアナロジーは、CPUは大学教授のようなものであり、さまざまな複雑な問題を独立して解決できますが、段階的に進むと、GPUは小学生のグループのようなものであり、シングルコアの計算能力はCPUほど良くありませんが、勝利は多数のコアにあり、同時に計算することができます。
黄が言ったように、CUDAは「科学的発展のための最良のソリューション」になり、巨大な計算能力がスーパーコンピューターを構築するための最初の選択肢になりました。
10月11日、米国エネルギー省傘下のオークリッジ国立研究所は、開発したスーパーコンピューター「サミット」が、スーパーコンピューター「Sunway Taihu Light」のほぼ2倍の速度である毎秒20億回の浮動小数点演算をピークにできると発表しました。
このコンピューティングパワーの巨人は、約28,000のNVIDIAGPUを搭載しています。 オークリッジ国立研究所は、NVIDIA の "CUDA+GPU" パッケージを採用した最初の機関です。
実際、NVIDIAが2006年にCUDAを立ち上げて以来、コンピューターコンピューティングに関連するすべての分野は、ほぼNVIDIAの形に形作られてきました。 航空宇宙、バイオサイエンス研究、機械および流体シミュレーション、およびエネルギー探査の研究の80%は、CUDAに基づいて行われています。
**さらに、大型モデルの流行に後押しされて、CUDAエコロジカルコラボレーターの規模は依然として倍増しています。 **
NVIDIAの2023年度年次報告書によると、現在400万人の開発者がCUDAを使用しています。 NVIDIAは12年間で200万人の開発者に到達し、過去2年半でその数を2倍にし、CUDAは現在4,000万回以上ダウンロードされています。
同時に、NVIDIAはまだCUDAエコシステムを拡大しており、ソフトウェアアクセラレーションライブラリのコレクションであるCUDA-X AIを立ち上げました。 CUDA上に構築されたこれらのライブラリは、ディープラーニング、機械学習、ハイパフォーマンスコンピューティングに不可欠な最適化機能を提供し、データサイエンスアクセラレーションのためのエンドツーエンドのプラットフォームです。
たとえば、AMDは、多くのコンピューティングフレームワークとも互換性のあるエコロジカルプラットフォームROCmを立ち上げました。 OpenAIのTritonは、CUDAの最強の挑戦者と見なされています。 Appleによって設計され、後にKhronos Groupによって保守されたオープンソースアーキテクチャであるOpenCLは、CUDAの成功を利用し、マルチコアCPU、GPU、またはその他のアクセラレータを可能な限りサポートします。 Googleは「TPU+TensorFlow + Cloud」モデルを使用して、開発者を引き付け、顧客を拡大しています。
しかし、これらの「理論的な」競合他社は、実際にはあらゆる種類の問題を明らかにしています。
2月、半導体調査・コンサルティング会社Semi Analysisの主席アナリストであるDylan Patel氏は、「機械学習におけるNvidiaのCUDA独占が破綻している方法-OpenAI Triton and PyTorch 2.0」というタイトルの記事を書いた。
記事のメッセージの中で、プログラマーは次のように述べています。
「そう願っていますが、私は非常に懐疑的です。 私が使用するものはすべてCUDA上に構築されています。 実際、NVidia以外のハードウェアには機能がありません。 「実際に効果的」は「理論的に効果的」と同じではありません。 私が使用するものの多くは理論的にはROCmをサポートしていますが、実際には、それを使用しようとすると、大小のバグが発生し、クラッシュしたり機能したりします。 "
** 第一線の研究者の発言は、ソフト・ハードともにトップの地位を保ち、20年近く市場を開拓してきたNVIDIAを前に、少なくとも現段階では、どの企業も正面から対抗できないことを証明している。 **
** 「世界を再発明する」から生まれたNVIDIA帝国**
NVIDIAがCUDAの切り札をつまんだのはなぜですか? 2006年にCUDAが発売されてから18年近くが経過したのに、なぜNVIDIAの堀は破られなかっただけでなく、どんどん広くなったのでしょうか。
これらの質問の背後にはデフォルトの前提があります - CUDAは「正しい」方向です。 そして、NVIDIAが必死だった21世紀の初めに、このフレーズHuang Jensenは株主と市場に何千回も繰り返しました。 **
素晴らしい世界を望むなら、まずはそれをシミュレートします。 ある意味で、このアイデアはGPU時代の起源であり、これらの複雑な物理法則をシミュレートし、それらを写真の形で提示します。 ただし、物理法則をシミュレートするアプリケーションは空から落ちることはなく、1つずつ開発する必要があります。
したがって、GPUの計算能力が将来CPUを超える可能性が高いことが示されたとしても、アプリケーションの欠如、プログラミングプロセスは面倒であり、低レベルの言語表現の欠如は依然としてプログラマーをそれから遠ざけます。
2003年、Intelは4コアCPUを導入し、競争するために、NVIDIAはユニファイドコンピューティングデバイスアーキテクチャテクノロジー(CUDA)の開発を開始しました。
**これらの称賛はすべてあとがきであり、黄が当時解決する必要があった問題は、回収期間が10年以上になる可能性のある未来のために戦うために製品のコストを2倍にする必要があることを株主に受け入れさせる方法でした。 **
実際、CUDAをめぐる疑念はAI時代前夜まで続き、NVIDIAの時価は長年10億ドル台で推移し、CUDAの追加費用の引きずりで株価は1.50ドルまで下落しました。 株主は、収益性の改善に焦点を当てることへの期待を繰り返し上げています。
2010年、当時のCPUの王様であるIntelは、Nvidiaの買収を計画していると噂されていました。 「Chip Wars」は、「インテルにとって、(Nvidiaの買収の)価格は問題ではなく、問題は黄ジェンクスンにどのようなポジションを与えるかです」と説明しています。 しかし、双方は合意に達することはなく、結局、それは解決されませんでした。 "
**弱気なNVIDIAのこれらすべての年において、黄はCUDAの価値に疑問を呈したことはありません。 **
開発者にアプリケーションを作成し、GPUの利点を実証するように促すために、Huangは最初に、当時ゲーマーにとってすでに大きな市場を持っていたGeForce GPUをCUDAをインストールするための基礎として使用しました。 その後、世界中でCUDAを精力的に宣伝するために、GTCと呼ばれる会議が作成されました。
近年最も賞賛されているケースの1つは、2016年にHuang Jenxunが当時確立されたOpenAIに個人的にアクセスして通信を行い、当時NVIDIAの最も強力な浮動小数点コンピューティングGPUであった8つのP100チップを搭載したDGX-1を発表したことです。
NVIDIAの決意とは対照的に、それはインテルです。
CPU時代の王として、インテルはNVIDIAの最も競争力のあるライバルになるはずでした。
しかし、2010年にCPUとGPUのコンバージェンスのためのディスクリートグラフィックス計画をキャンセルした後、IntelはNVIDIAと直接対決することに興味を失いました(もちろん、ナノプロセスが行き詰まったため、自信を失ったと言えます)。 **最初にNVIDIAの買収を試み、その後、モバイルベースバンド市場でクアルコムと向きを変えて競争し、2015年に人工知能ブームの最初の波が押し寄せたとき、大きな夢で目覚めたIntelは、片手で人工知能の方向にチップ会社を買収し、AMDのチップを独自のシステムチップに組み込みました。
残念ながら、当時、NVIDIAの市場シェアは60%を超え、CUDAの独占が具体化し始めており、GPU分野では、IntelはNVIDIAと同じテーブルに座る資格がなくなりました。
DPU と DOCA、NVIDIA の新しい戦場
2020年、ベンチャーキャピタル界で人気のジョークがありました。
「DPUとは何ですか?」
「アリペイが到着しました、1億元。」
キーワードDPUがトリガーされるとすぐに、お金がロールインします。
DPU熱のこのラウンドは、まさにNVIDIAが始めたものです。
2020年上半期、NVIDIAはイスラエルのネットワークチップ会社メラノックステクノロジーズを69億ドルで買収し、同年にBlueField-2 DPUを発売し、CPUとGPUに次ぐ「第3のメインチップ」と定義しました。
**では、DPUとは正確には何ですか? **
**DPUのコア機能は、CPUを置き換え、データ中心のコンピューティングアーキテクチャを確立することです。 **
ご存知のように、CPUのフルネームは中央処理装置であり、アプリケーションの実行と計算の実行に加えて、GPU、ストレージ、FPGA、その他のデバイス間でデータを移動するデータフローコントローラーの役割も果たします。
校長先生が難しい問題を投げた後、先生(CPU)が分割し、より複雑な部分は自分で解決し、生徒(GPU)に配布するのは簡単ですが面倒です。 以前は、質問の数は比較的少なく、教師はまだそれを分割することができました。 ただし、質問の数が増えると、質問を分割して配布する時間が教師の時間の多くを占めます。
現時点では、トピックの分割と配布を専門とする人を雇うことが、システムの全体的なコンピューティング効率を向上させるための鍵となっています。 そしてDPUはその人です。
**近年、データセンター構築の急速な拡大、ネットワーク帯域とデータ量、CPUパフォーマンスの成長の鈍化により、将来のコンピューティングチップのニーズに適応することがますます困難になり、DPUが登場しています。 **これはNVIDIAのウェブサイトで定義されている方法です-DPUはデータセンターインフラストラクチャのための高度なコンピューティングプラットフォームです。
DOCA を使用すると、開発者は、ソフトウェア定義のクラウドネイティブな DPU アクセラレーション サービスを作成することで将来のデータセンター インフラストラクチャをプログラムし、ゼロトラスト保護をサポートして、最新のデータセンターの増大するパフォーマンスとセキュリティの要求を満たすことができます。
CUDAとは異なり、すでに成功しているNVIDIAは、ベンチャーキャピタルサークルのDPU熱がこれを説明するのに十分であるため、市場に独自のビジョンを丹念に証明する必要がなくなりました。
ただし、それに伴い、DPU市場での競争はGPUよりもはるかに熾烈です。 **
外国メーカーでは、マーベル、インテル、AMDがDPUまたはDPUアライメント製品を開発しています。 中国では、Yunbao Intelligence、Zhongke Yushu、Xinqiyuan、Yunmai Xinlian、Nebulas Zhilian、Dayu Zhixinなど、多くのDPUスタートアップも出現しています。
クラウドベンダーに関しては、AmazonのAWSとAlibaba Cloudが大規模な商用DPUアーキテクチャを実現し、TencentとByteDanceがDPUの研究開発軍に加わり、そのうちTencentはMetasequoiaとYinshanの2世代のDPUを立ち上げました。
今回、NVIDIA は DPU+DOCA のソフトウェアとハードウェアのエコロジーを利用して、GPU + CUDA の奇跡を再現できるでしょうか。
**国と企業間の計算能力をめぐる競争は激化しており、生産能力が限られており、DOCAエコシステムがまだ形成されていない場合、対戦相手には機会がないわけではありません。 **